

AI Content Generation, Part 1: Machine Learning Basics
This technology is already changing the creative industry. Here's how it works.

Welcome to the first installment of my new tutorial series on AI content generation. Part 2 covers tasks and models. Part 3 is a deep dive into Stable Diffusion. Part 4 is a look at what’s next for AI content generation. Sign up now to make sure you don’t miss future installments!
If you’re building in any of the spaces I cover in this Substack, then you can use this form to tell me about it and I may be able to help you get connected with funding.

I love those fake modern-day Seinfeld bits people post to Twitter. Just recently, the one below had me rolling because I can really picture the entire scene and hear all the actors’ voices in myd:

If you’ve been following the red-hot AI content generation scene, then you’re probably already aware that it’s likely a matter of months before authentic-looking video of newly invented Seinfeld bits like this can be generated by anyone with a few basic, not-especially-technical skills. Instead of tweeting little 250-character dialogues like the one above, Seinfeld fans will tweet video clips complete with flawlessly matching laugh tracks.

A technology called deep learning is bringing what can only be described as miracles within the reach of ordinary creators. Whether you’re making text, images, video, or code, and whether you’re looking to work alongside an AI or have the AI do most of the work for you, you’re about to get superpowers.
In fact, AI superpowers are already here for creators who are willing to invest a little time in understanding how these machine learning-based content tools work. In this new series of posts, I’ll give you an overview of the content generation space, covering everything from the ideas behind it to how to use specific tools.
Who this introduction is for:
Content creators who want to use these tools to enhance their work, but aren’t quite sure where to start.
Creators who may not be quite ready to take the plunge, but who do want to understand the role this technology is playing in the markets where they’re trying to make a living.
Journalists and academics who are trying to understand the impact this technology will have on society.
Investors and builders who are looking for good places to get involved in the space.
How to get the most out of this series
AI content generation is a very rapidly evolving space — I’ve started on a few tutorials for specific tools (watch this space for those to come out) and found that things can literally change by the hour, as new builds are pushed out. There’s also a constant stream of new tools launching, a testament to investor interest and market demand.
Given the amount of churn and evolution in the AI content ecosystem, the best way to come to gain a profitable working knowledge of it is to invest a bit of time in understanding it on its own terms. This doesn’t mean you need to know how deep learning works, how to do matrix math, what a transformer is, or any other low-level concepts. Rather, you need a functional, high-level sense of what’s going on behind the scenes of all these apps and tools, because the behind-the-scenes stuff doesn’t change nearly as fast as the user-facing tools do.
I’ve divided up the core concepts you need to know by level, from lowest level to highest level:
Machine learning basics. (This article)
Applications. (Coming soon…)
Each article in this series will cover one of these levels, and I’ll also publish a few detailed “click this, type that” articles at the “Applications” level that walk you through how to get started with specific tools.
Note that the rate of change of the field gets faster as you move up each level. So machine learning basics are the most stable layer, and the knowledge you gain about this area will remain useful for the longest. Contrast this to the top layer, where there are so many products launching that this part of the present article will already be slightly out-of-date by the time I publish it.
Here’s main the advantage of starting at the bottom and working up: all the changes in a layer are built from concepts in the layers below; so if you understand layers 1 and 2, then you’ll immediately be able to grasp and use new (or iterated) products in layer 3.
The bottom line: If you skip the core concepts laid out in the next few sections and jump straight to the tools in subsequent installments, you’ll miss most of the value of this post. So read the parts of this post that will stay useful the longest, and skim the more practical content that follows with a plan to revisit it as-needed.
The three things you can do with machine learning
All the AI content generation tools I’ll cover in this series can be lumped into one of three main categories:
Generation: This is probably what you’re here for, i.e., using ML to make new things.
Classification: All forms of analysis, feature/object extraction, and so on go in this bucket.
Transformation: This includes translating languages, but there are plenty of other tasks that you might want to do that fall under the heading of transforming an input into a tweaked or altered version of itself.
I’ve made an Airtable of some AI-based content tools I’ll cover in this series, tagged by the three categories above.
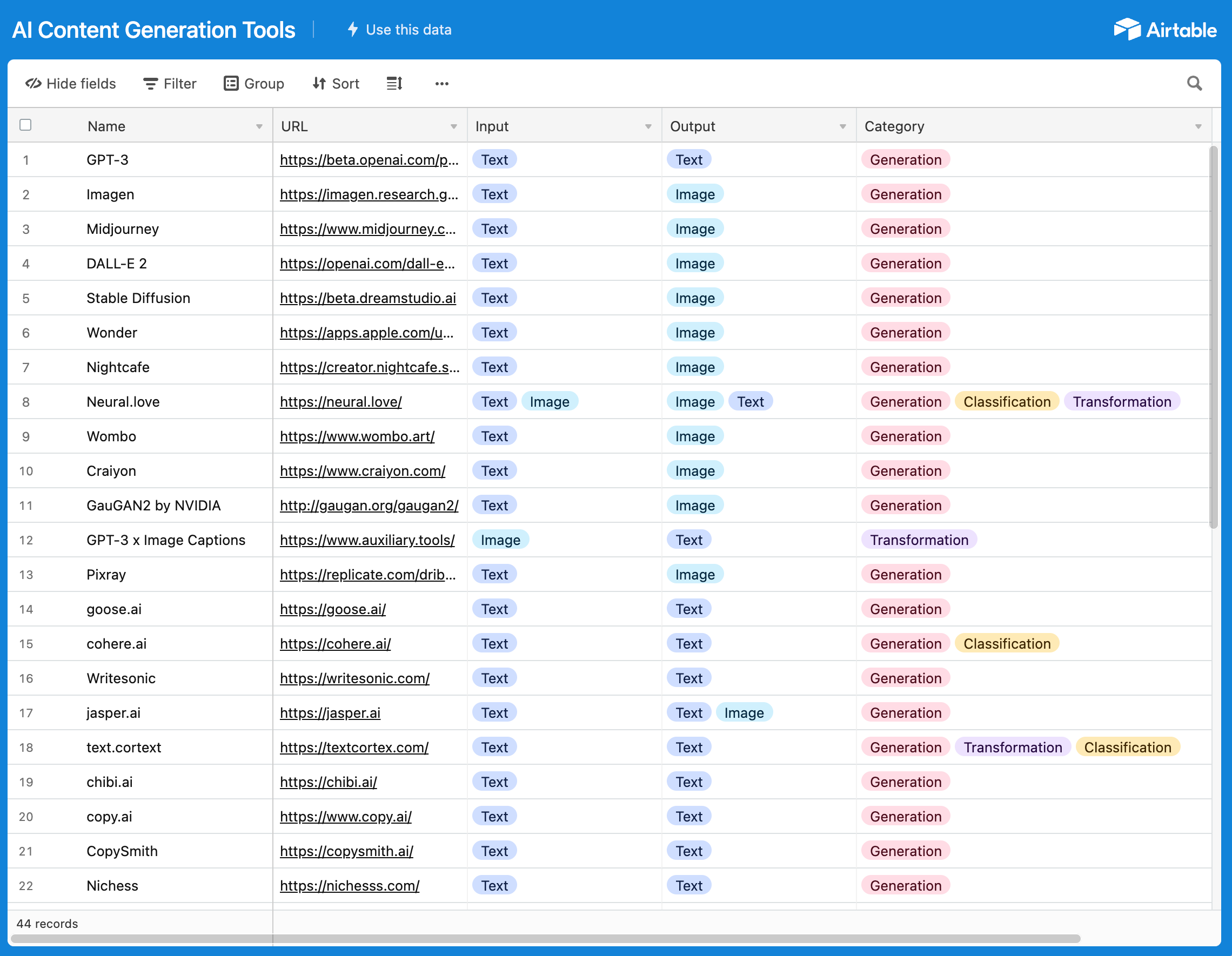
Note that many of these tools do multiple things, and as we’ll soon learn the line between one category and another can sometimes be arbitrary.
Machine learning basics
What if I told you that every configuration of bits that can possibly exist — every abstract concept or idea, every work of art, every piece of music, everything we can put into a digital file for display or playback on a computer or in a VR headset — is already out there on the number line and that the act of turning any given chunk of information into a readable file involves first locating that thing in the eternal, pre-existing space of numbers and then reversing enough local entropy to give that number a physical form?
This sounds woo, and maybe it is, but it’s a very useful way to look at the world if you want to understand machine learning. That’s because a trained AI model contains a kind of internal representation of a (hopefully useful and interesting) chunk of the space of all possible digital files. When we use these models, we’re poking around in that space to see what we can find.
See the Appendix at the bottom of this article for more on this fascinating topic.
Every input you give an AI is really a search query

The animation above shows me entering a text prompt into GPT-3 and getting an output in reply. You might naively imagine that this prompt is a type of command — that I’m ordering GPT-3 to do a thing for me (in this case, to create a new block of text). That’s certainly one way to think of a prompt, but it’s not the best way, nor is it the way ML researchers and AI experts think of prompts.
A better way to think about what’s going on in the animation above is to think of the prompt as a search query, exactly like the kinds of queries you’d type into Google to locate a particular piece of information on Google’s servers. You’re sending a search query to the model, and the model then does the following steps:
Translates your input query into a set of coordinates on the surface of all possible digital files (that it has seen before and knows about), and then
Returns to you as output the file that’s closest to your coordinates in that space (often after going through multiple iterative steps of narrowing in on the target).
So when you feed a model like GPT-3 or Stable Diffusion a prompt, what’s actually going on behind the scenes is you’re giving the model some direction about where in the space of its possible outputs to begin looking in order for it to locate the thing you’re asking it to “generate.”
This “search query” framework is useful because it lets you magically import all the intuitions and skills you’ve built up from years of searching Google, and turn them to the task of AI content generation more or less unaltered.
Most Google users might start with a general query, and then refine the query over multiple searches in order to steadily narrow down the list of results to suit their goals for that session. You’ll use this exact same process with many AI content generation tools:
Give the tool a search query
Evaluate the results
Tweak the query, then return to step #1.
Just like Google has in its vast servers an organized, structured representation of a portion of all the web pages in existence on the internet, a language model like GPT-3 or an image generation model like Imagen has in its internal “memory” an organized, structured representation of all the text or images it was trained on.
And just like Google has “memorized” only the part of the web it has crawled, Stable Diffusion has “memorized” only the part of the space of all possible images it has been trained on.
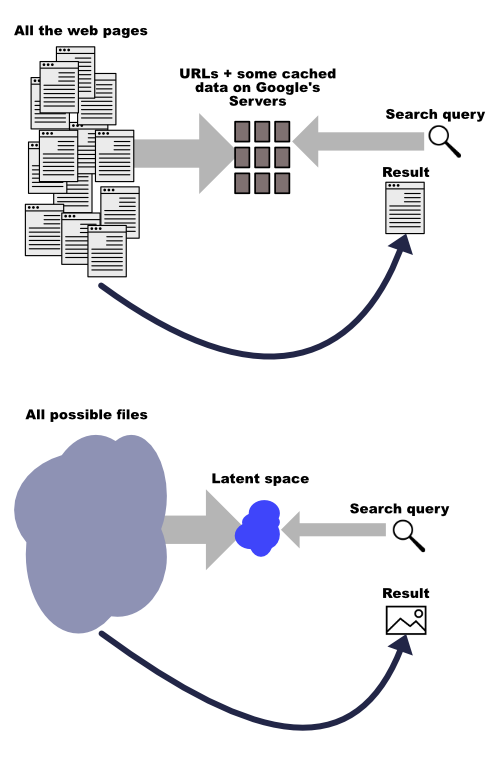
We can now make the following useful mental mappings between web search-related concepts and AI image generation-related concepts:
Crawling => training
Searching => prompting
Refining a search => refining a prompt
Filtering a search => setting parameters on the model
The bottom line: When using AI content generation tools, it’s best to think of the prompts you’re feeding them as a search query instead of a command. The skills and intuitions you already have from using Google will help you when it comes to crafting a suitable prompt for a model.
Nuancing the picture with latent space
If content generation is really a form of search, then you’re probably wondering how categorization and analysis fit into this picture. I could explain this using the integer and timeline language introduced earlier, but you’ll gain a better sense of how AI does what it does if we nuance the picture a bit.
Instead of thinking of every digital file on your hard drive as a single, really large integer, try imagining that it’s a group of three integers that form a set of coordinates to a point in 3D space, like the point at the x, y, and z coordinates in the image below.
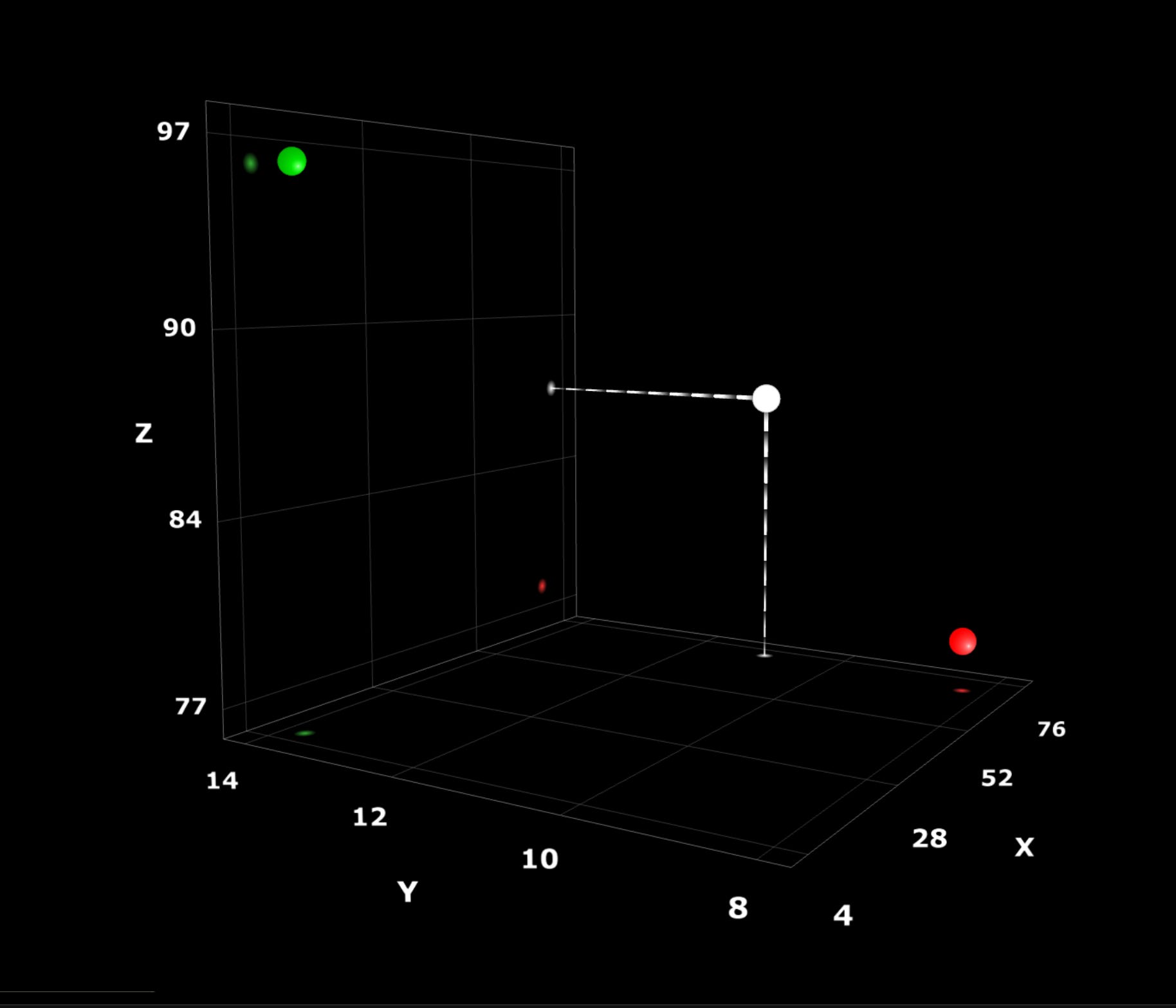
Consider the example of a file that’s a color picture of a vehicle of some type. Let’s say we wanted to turn that digital picture into a single point in 3D space and plot it on a 3D plot like the one above. (I’ll get to why we’d want to do this in a moment.) To do this, we need to figure out which aspects of the picture will form our x, y, and z axes:
Dimensions and color: We could make the height of the picture (in pixels) the x-axis, the width of the picture the y-axis, and the average color of all the pixels the z-axis.
Abstract concepts: We could make the three axes could be “automobile,” “horse-and-buggy,” and “bicycle,” and we could plot the photograph as a single point on the graph by measuring how close it is to one of these three concepts. A picture of a motorcycle, for instance, might sit in the region between “automobile” and “bicycle,” while a picture of a tricycle pulling a wagon might sit in the region between “horse-and-buggy” and “bicycle.”
Ultimately, we’ll pick whatever three characteristics of pictures are most important to us, and then use them to turn our picture into a single point in 3D space.
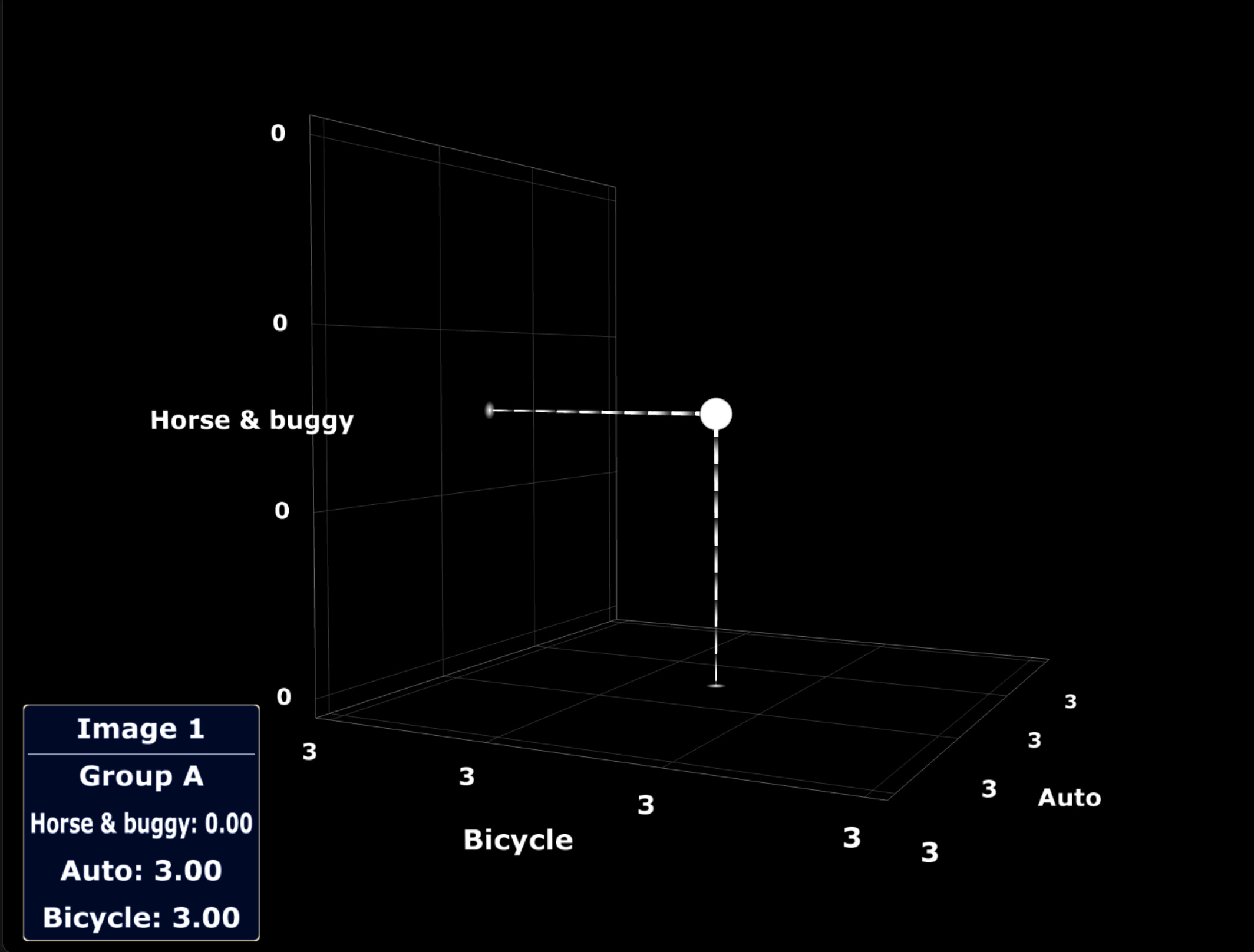
Let’s say we apply the “automobile” vs. “bicycle” vs. “horse-and-buggy” coordinate scheme to a picture of a motorcycle. If we’re scoring each of these three attributes on a scale of 0 to 10, with 0 having the least “automobileness” (or “bicycleness,” or “horse-and-bugginess”) and 10 having the most. If we gave the motorcycle a score of 3 automobile, 4 bicycle, and 0 horse-and-buggy, we’d get something like the following plot:
We can’t do much with a single point in space, so we’ll repeat the process above — let’s use — on a folder of 10 pictures, all showing some form of vehicle.

Plotting the above dataset using the automobile/bicycle/horse-and-buggy scheme might give us a 3D shape that looks something like the following:
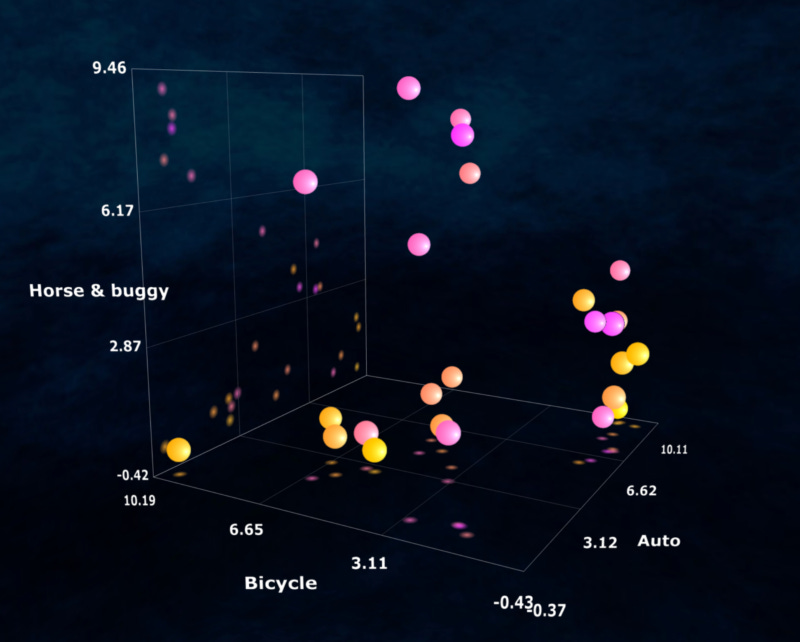
Even if you hadn’t seen a copy of the pictures in the folder, you could actually glance at this shape and tell that most of the pictures in that directory are some kind of automobile. Just from looking at the shape of the 3D volume, the points make when they’re distributed along the x, y, and z axes, we can infer useful things about the dataset as a whole.
The internal “memory” of a deep learning model consists of a multidimensional version of something like the simple volume above. The training process for an image model like Stable Diffusion involves showing the model a large number of pictures so that it can extract different features and qualities of the pictures (like “automobileness,” “bicycleness,” or “horse-and-bugginess”). It then clusters compressed representations of images together in this multidimensional space, so that different regions of it tend to correspond to similar types of images.
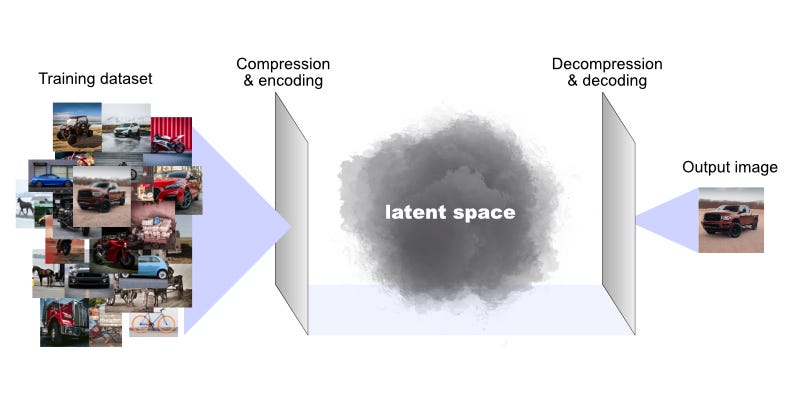
The finished, trained model, then, is a highly compressed, digital representation of a multidimensional space of concepts and features — a latent space — that the machine has extracted from the training dataset during its training phase. In this space, similar things tend to be clustered near one another along one or more dimensions, while unlike things are located further apart.
Note that the model’s latent space doesn’t literally store images in a readable file format like JPG or PNG, and then organize these files together somehow. It’s not a database. Rather, the model’s configuration of numerical weights stores different attributes and features of a training image — edges, shapes, colors, and even abstract concepts related to what’s depicted — in such a way that a configuration of bits adjacent to (and therefore similar to) that image can be recovered from the space of all possible digital files by pointing queries at the region of latent space that the training image has left unique impressions on.
Adding text to the image data
When Stable Diffusion was trained, it wasn’t trained solely on images. Rather, the images had relevant text with them, so this text is also organized in the model’s latent space alongside the relevant images.
Pinterest was allegedly a big source of training data for Stable Diffusion, so this is the kind of thing the model would have seen when it was being trained:
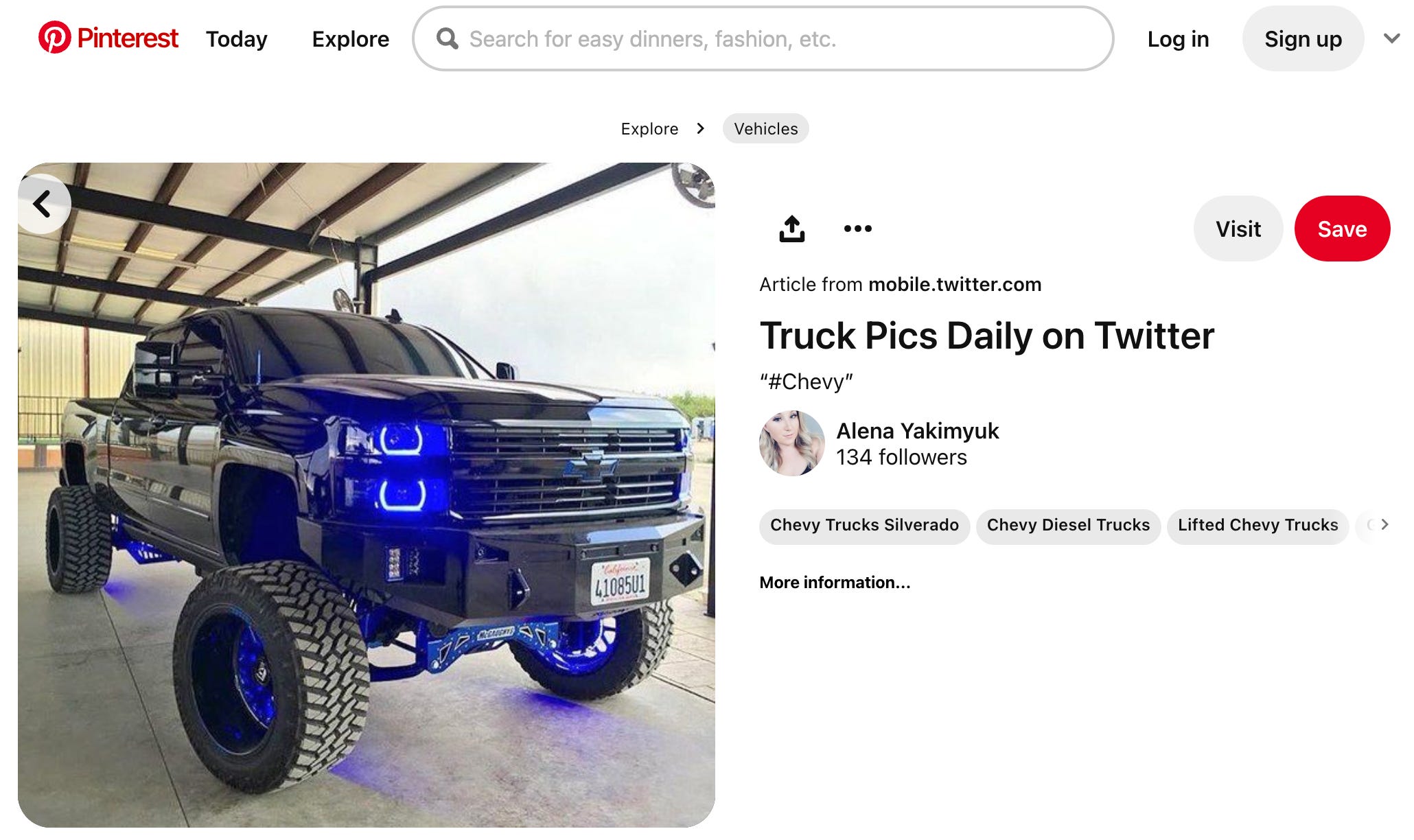
The tags, description, and other text associated with the image above on the Pinterest page would have probably been sucked into the model along with the image itself so that those terms are clustered near the truck in the model’s latent space.
It’s important to note that while text associated with an image is the model’s only source of English (or whatever language) words that it can associate with concepts, the concepts would still be there in the model even if we were to leave out the words. The model would still figure out, based on images alone, that trucks are different from cars, which are different from bicycles, which are different from covered wagons. We’d have no way to locate those concepts by inputting English words into the trained model, but they’d still be there in latent space.
Generation, classification, and transformation
We already saw how AI content generation really amounts to searching a space of possible digital files using a specially constructed search query, but now that we know more about how models are trained, we can see that all three of the core functions of AI content tools are all really just variants on search. Depending on the type of task you’re doing, you’ll give the model a particular type of input and ask it for a particular type of output.
For image generation models like DALL-E 2, Stable Diffusion, and Imagen, the process breaks down as follows:
Generation: text => image
Classification: image => text
Transformation: image => image (or text => text)
When you’re doing “AI content generation,” then, you’re using a text query to return the image that’s at a point in the latent space. When you’re doing “AI image classification,” you’re using an image query to return the text that’s near the input image in latent space. And when you’re doing an image transformation or a even text summary, you’re searching the latent space for a file that’s near the file you used as input.
It should now be clear why people toss Google-query-like terms into their DALL-E prompts, terms like “trending on artstation",” “unreal engine,” and so on. Such terms get your query nearer to the part of the model’s latent space that represents knowledge about the input images that these words associated with them in the training phase.
Appendix: The metaphysics of numbers
When you count up to a new whole number that you personally have never counted up to (or summed or multiplied up to) before, would you claim to have “created” or “invented” that whole number, or even to have “discovered” it? None of these terms really feels right, so maybe it’s we can just say you “found” it, or “stumbled across” it, or “located” it.
Most people’s intuition about numbers — especially whole numbers (i.e., numbers without a decimal place) — is that they “exist” in some meaningful way as an “objective” part of the universe. The sense that we have when we’re counting, multiplying, adding, subtracting, or doing other mathematical operations, is not that each result is a brand new number that’s coming into the world, but that we’re merely producing a representation of a number that already exists.


Here’s the weird part (at least, it’s weird for me… your mileage may vary): every digital file of any size is also an integer, or rather it’s more accurate to say that every file has a single integer representation. If I have a very small digital file that consists only of the bits 0010, then the integer version of that file is 2. And on it goes out to files zettabytes in size and integers that are larger than the number of atoms in the universe.
So to the extent that numbers somehow “exist” out there in reality apart from what we humans think or say about them, every digital file that you could put on a computer — every iTunes music download, every movie, every picture, every podcast — already “exists” on the regular old integer number line we all know from grade school. Every file on your laptop was “real” as an integer before you represented it in little electronic pulses, and that integer would still be “real” even if you were to launch your laptop into the sun.
The question of “what does it mean to say that numbers really exist?” is an old one for philosophers, but computers in general and AI in specific bring this esoteric question into the realm of things it’s useful for non-nerds to ponder.
The reason this question suddenly matters for you as a sophisticated user of AI in your daily life is that taking it seriously will give you a set of useful intuitions about how AI works — intuitions that you’ll share with the people who develop AI for the rest of us to use, and that will guide you not just the “how” but the “why” of specific platforms, user interface elements, and best practices.
Borges's Library of Babel is my favorite treatment of the “what does it mean to say that numbers really exist?” question.
Jon, the real-ness of numbers reminded me of the twins in Oliver Sacks "The Man Who Mistook His Wife for a Hat"... The relevant section is posted here:
https://empslocal.ex.ac.uk/people/staff/mrwatkin/isoc/twins.htm
Some are skeptical of the story... But there's got to be patterns we humans don't (yet?) perceive...