


ChatGPT Explained: A Normie's Guide To How It Works
Once you understand a few core concepts, modern chatbots are less mysterious.


The story so far: Most of the discussion of ChatGPT I’m seeing from even very smart, tech-savvy people is just not good. In articles and podcasts, people are talking about this chatbot in unhelpful ways. And by “unhelpful ways,” I don’t just mean that they’re anthropomorphizing (though they are doing that). Rather, what I mean is that they’re not working with a practical, productive understanding of what the bot’s main parts are and how they fit together.
To put it another way, there are some can-opener problems manifesting in the ChatGPT conversation, and lowering the quality of The Discourse.
To be clear, I do not know everything I’d like to know about this topic. Like everyone else, including active researchers in machine learning, I’m still on my own journey with getting my head around it at multiple levels. (Speaking of, if you run a shop that sells dedicated ML workstations and would like to publicly sponsor this newsletter by sending me one, do get in touch.)
That said, I’m certainly far enough along that I can help others who are a few steps behind. So what follows is my effort to help others get closer to the target in their thinking and writing about this new category of technology.
Machine learning: the super basic basics
At the heart of ChatGPT is a large language model (LLM) that belongs to the family of generative machine learning models. This family also includes Stable Diffusion and all the other prompt-driven, text-to-whatever models that are daily doing fresh miracles on everyone’s feeds right now.
If you want to know more about how generative ML models work and you have some time, read the following pieces:
⭐️ But if you don’t have time to read all that, here’s a one-sentence explanation of a generative AI model: a generative model is a function that can take a structured collection of symbols as input and produce a related structured collection of symbols as output.

Here are some examples of structured collections of symbols:
Letters in a word
Words in a sentence
Pixels in an image
Frames in a video
Now, there are plenty of ways to turn one collection of symbols into another, related collection of symbols — you don’t even need computers to do this. Or, you can write a computer program that uses rules and lookup tables, like a certain famous chatbot from the 60s that I’m sick of hearing about.
👷♂️ The hard and expensive part of the above one-sentence explanation — the part that we’ve only recently hit on how to do using massive amounts of electricity and leading-edge computer chips — is hidden deep inside the word related.
Quick concepts: deterministic vs. stochastic
Before we get into relationships, you need two concepts that will come up again and again throughout this piece:
⚙️ Deterministic: A deterministic process is a process that, given a particular input, will always produce the same output.
🎲 Stochastic: A stochastic process is a process that, given a particular input, is more likely to produce some outputs and less likely to produce others.
A classic gumball machine is deterministic — if I insert a quarter and turn the crank, I get a single gumball every time. So one quarter == one gumball, always.

But a classic gumball machine is also stochastic — if I put in a quarter and turn the crank, the color of the gumball I’ll get is fundamentally random. Furthermore, the odds of getting one color or another depends on the ratios of different colors inside the machine. Five different gumball machines with five different gumball color ratios will have five different probability distributions for gumball color output.
Now, with these key concepts out of the way, back to the reason why relationships can be hard.
Relationship matters
Collections of symbols can be related in different ways, and the more abstract and subtle the relationship, the more technology we’ll need to throw at the problem of capturing that relationship in a way that’s useful for knowledge work.
If I’m relating the collections
{cat}and{at-cay}, that’s a standard “Pig Latin” transformation I can manage with a simple, handwritten rule set.If I’m relating
{cat}to{dog}, then there are many levels of abstraction on which those two collections can relate.As ordered symbol collections (sequences), they both have three symbols.
As three-symbol sequences, they’re both words.
As words, they both refer to biological organisms.
As organisms, they’re both mammals.
As mammals, they’re both house pets. And so on.
If I’m relating
{the cat is alive}to{the cat is dead}, then there’s an even larger number of even more higher-order concepts that we can use to compare and contrast those two sequences of symbols.All of the concepts related to
catare in play, as are concepts related to “alive” vs. “dead.”On yet another level, many readers will spot what we might call an intertextual reference to Schrödinger’s Cat.
Let’s add one more relationship, just for fun:
{the cat is immature}vs.{the cat is mature}. But are we talking about a stage of physical development or a state of emotional development?Since it’s a cat, “immature” is probably a straightforward synonym for “young” or “juvenile.”
If the subject of the sentence were a human, the sentence would more likely be invoking a cluster of concepts around age-appropriate behavior.
📈 As you read through the list of items above, you can imagine that as you go up in number from one to four there’s an explosion of possible relationships between the symbols. And as the number of possible relationships increases, the qualities of the relationships themselves increase in abstraction, complexity, and subtlety.
The different relationships above take different classes of symbol storage and retrieval — from paper notebooks up to datacenters — to capture and encode in a useful way.
That first, simplistic Pig Latin relationship can be described on a single sheet of paper, such that anyone with that paper can transform any word from English into Pig Latin. But by the time we get to example four, a strange thing has happened, and that strange thing is why machine learning requires tens of millions of dollars worth of resources:
We’ve uncovered a small universe of possible relationships between those collections. There’s just a bewildering, densely connected network of concepts, all the way up the abstraction ladder from simple physical characteristics, to biological taxonomies, to subtle notions of physical and emotional development.
Some of the more abstract possible relationships are more likely to be in play than others. So an element of probability has entered the picture.
As I said in the example, given that we’re talking about a cat, it’s more likely that the mature/immature dichotomy is related to a cluster of concepts around physical development and less likely that it’s related to a cluster of concepts around emotional or intellectual development.
Regarding the probabilities in #2 above, “less likely” does not mean impossible, especially if we open the door to a bit of extra context. What if we added a few additional words, and the collection pair was:
{Regarding the cat in the hat: the cat is mature.}{Regarding the cat in the hat: the cat is immature.}
🌈 Suddenly, all the probabilities have shifted and we’re in a whole other realm of likely meaning with respect to maturity and immaturity.
Summary:
When the relationships among collections of symbols are simple and deterministic, you don’t need much storage or computing power to relate one collection to the other.
When the relationships among collections of symbols are complex and stochastic, then throwing more storage and computing power at the problem of relating one collection to another enables you to relate those collections in ever richer and more complex ways.
Quick concept: probability distribution
If you managed to get through high school chemistry, then you have a set of concepts that are useful for thinking about generative AI: atomic orbitals.
😳 And if you didn’t get through basic chemistry, or you don’t remember any of it, then don’t worry. This section is mostly about the pictures, so look at the pictures and scan for the boldfaced words, then move on.
We all learn in basic chemistry that orbitals are just regions of space where an electron is likely to be at any moment. Electrons at different energy levels have orbitals that are shaped differently, which means we’re likely to find them in different regions.
Take a look at hydrogen:
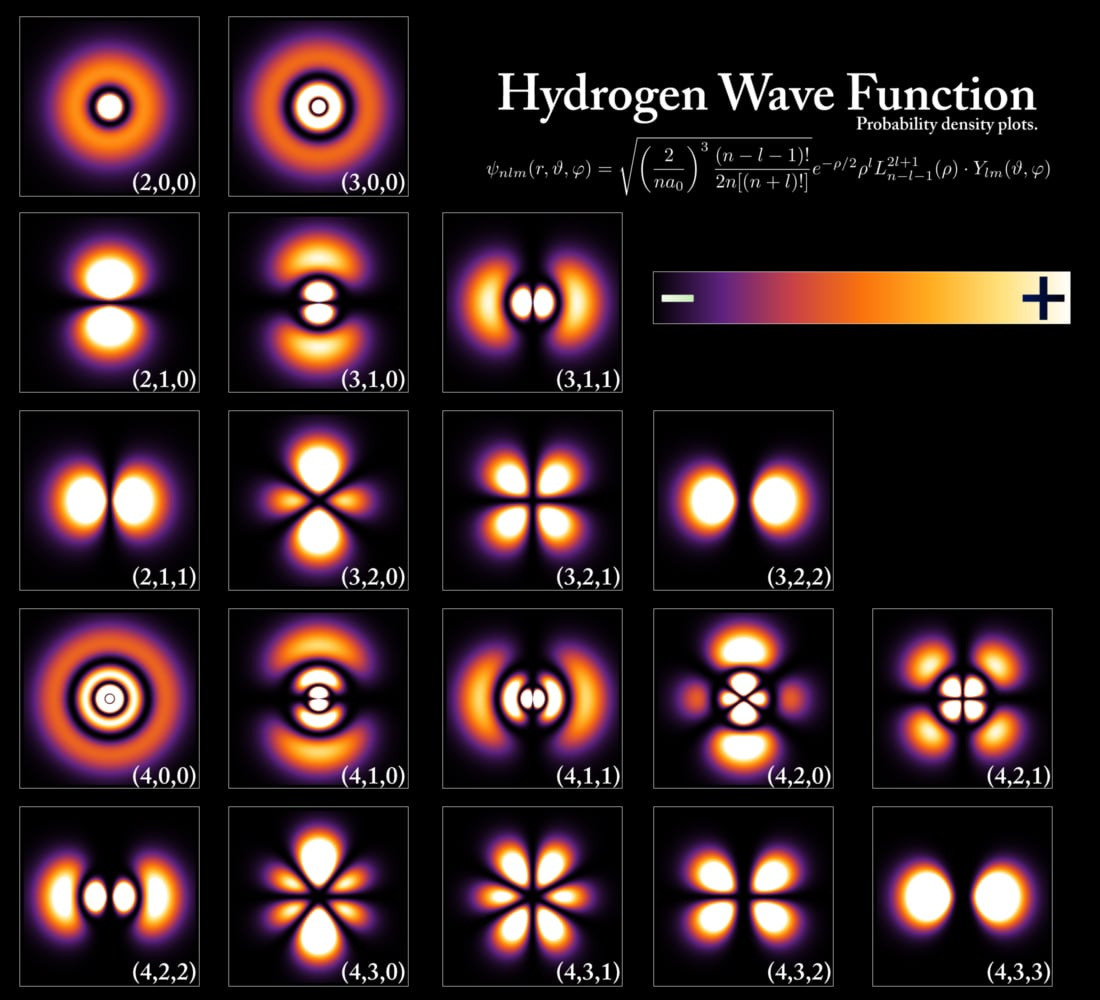
Let’s zoom in on one of the orbitals:

For the orbital above, the brighter the region the higher the odds you’d bump into an electron there if you were to poke at the atom with something even tinier than an electron. For the black regions in the picture, that doesn’t mean the probability of finding an electron is zero — it just means it’s so low as to practically be zero.
Those orbitals are probability distributions and they have a certain shape to them — the one above has four lobes, so that if you observe a point in one of those four areas you’re more likely to spot an electron than if you observe one of the black regions. The other orbitals have different lobes that are arranged in different ways.
🥳 Ok, you made it! That’s all the quantum chemistry you need, and in fact, it’s all the background you need at the moment. We can now talk about the thing everything is trying to understand: ChatGPT.
ChatGPT doesn’t know facts or have opinions
You can imagine that for a model like ChatGPT, each possible blob of text the model could generate — everything from a few words of gibberish to a full page of coherent English — is a single point in a probability distribution, like electron positions in the atomic orbitals of the previous section’s hydrogen atom.
When you feed ChatGPT’s input box a collection of words — e.g. {Tell me about the state of a cat in a box with a flask of poison and a bit of radioactive material} — you can think of that action of clicking the “Submit” button as making an observation that collapses a wave function and results in an observation of a single collection of symbols (out of many possible collections).
🧠 Note for more informed readers: Some of you who read the above will be aware that a text-to-text LLM is actually locating single words in the probability space and successively stringing them together to build up sentences. The distinction between “latent space is the multidimensional space of all likely words the model might output” vs. “latent space is the multidimensional space of all likely word sequences the model might output” is pretty academic at this level of abstraction, though. So for the purpose of downloading better intuitions into readers and minimizing complexity, I’m going with the second option.
🎲 Sometimes, your text prompt input will take you to a point in the probability distribution that corresponds to a collection like, {The cat is alive}, and at other times you’ll end up at a point that corresponds to {The cat is dead}.
Note that it is possible, though not at all likely, that the aforementioned input symbols could take you to the point in the model’s latent space corresponding to the following collection: {ph'nglui mglw'nafh Cthulhu R'lyeh wgah'nagl fhtagn}. It all depends on the shape of the probability distributions you’re poking at with your text inputs and on the dice that the universe — or, rather, the computer’s random number generator — is rolling.
👉 Important implication: It’s common but not necessarily always useful to say the language model “knows” the state of the cat in this example — i.e., whether it’s alive or dead. It’s suboptimal to lean too hard on the idea that the model has a kind of internal, true/false orientation to the cat and different claims about its circumstances.
Instead, it’s better to think of it like this:
➡ In the space of all the possible collections of symbols the model could produce — from collections that are snippets of gibberish to collections that are pages of Shakespeare — there are regions in the model’s probability distributions that contain collections of symbols we humans interpret to mean that the cat is alive. And there are also adjacent regions in that probability space containing collections of symbols we interpret to mean the cat is dead.
🐈 Here are some cat-related symbol collections we might encounter in ChatGPT’s latent space — i.e., the space of possible outputs, which has been deliberately sculpted into a particular shape by an expensive training process:
{The cat roused herself from slumber and blinked her eyes.}{The soft breathing of the sleeping cat greeted Schrödinger as he opened the box.}{Ja mon, de cat him dead.}{“I’ve killed my favorite cat!” screamed Schrödinger as he pulled his pet’s lifeless corpse from the box.}{Patches watched the scene from above, his astral cat form floating near the ceiling as his master lifted his lifeless body from the box and wept.}
When you poke at the model with different input collections, you’re more likely to encounter some of these output collections than others, but they’re all at least theoretically possible to encounter.
👎 So when you and I are both interacting with ChatGPT around a topic that’s related to some set of facts in the world — e.g., the status of the Bengal tiger, and if it’s endangered or not — don’t imagine that we’re both asking some unitary entity with a personal history and set of experiences to communicate to us some of the facts about Bengal tigers that it has tucked away in its memory, where if it tells you one thing and me the opposite then it’s somehow lying to one of us.
👍 Rather, think of our activity like this: I am using my text prompt to observe a single point in a probability distribution that corresponds (at least on my reading of the model’s output symbols) to a cluster of facts and concepts around Bengal tigers, and you are doing the same thing. When both of us are getting different sequences of words that seem (again, to us as humans who are interpreting this sequence) to represent a divergent fact pattern — e.g., it tells me the tiger is endangered, and it tells you the tiger is so prevalent that it’s a nuisance animal — it’s because we’re poking at different lobes of a probability distribution and finding different points in those divergent lobes.
The lobe in the probability distribution that I’m poking at encompasses word sequences that generally correspond to what I, a human English speaker, interpret as claims about the endangered status of Bengal tigers.
The lobe you’re poking at encompasses word sequences that generally correspond to what you interpret as claims about the superabundance of Bengal tigers.
So how do we fix this?
Given that the Bengal tiger is, in fact, endangered (or, at least this is what I take to be the state of the world based on the words that Google’s ML-powered machines are telling right now when I type in a search query), how do we eliminate or at least shrink the probability distribution lobe that you’re poking at — the one that covers text blobs about Bengal tigers overrunning the cities, digging in people’s garbage, and other nonsense?
✋ Not only is it not clear we can, but it’s also not really clear we’d always want to. Let me explain.
Hallucination: feature or bug?
When an LLM spits out a word combination that an observer takes to misrepresent the state of reality, we say that the model is “hallucinating.”
😵💫 Aside: I gotta say, this “hallucination” term is pretty loaded. His hallucination is her mythopoesis is my prophecy of things which must shortly come to pass (he who has ears to hear, let him hear). Wars have been fought over this stuff, and may be yet again if a famous collection of alleged hallucinations is interpreted as “true” in some way… But let’s not get ahead of ourselves by veering into hermeneutics just yet. We’ll pick up this thread again in a moment.
Right now in early 2023, we have a set of tools that allow us to shape an LLM’s probability distributions, so that some regions get smaller or less dense and some regions get larger or denser:
Training
Fine-tuning
Reinforcement learning with human feedback (RLHF)
🏋️ We can train a foundation model on high-quality data — on collections of symbols that we, as human observers, take to be meaningful and to correspond to true facts about the world. In this way, the trained model is like an atom where the orbitals are shaped in a way we find to be useful.
🪛 Then after poking at that model for a bit and discovering regions in the space of likely outputs that we observers would prefer to stop encountering in the course of our observations, we fine-tune it with more focused, carefully curated training data. This fine-tuning shrinks some lobes and expands others, and hopefully, after poking some more at the results of this lobe-shaping process we’re happier with the outputs we’re seeing when we collapse the wave function again and again.
👩🏫 Finally, we can bring in some humans in the RLHF phase to help us really to dial in the shape of the model’s probability space so that it covers as tightly as possible only the points in the space of all possible outputs that correspond to “true facts” (whatever those are!) about things in the world, and so that it does not cover any points that correspond to “fake news” (whatever that is!) about things in the world. If we’ve done our job right, then all the observations we make of the model’s probability space will seem true to us.
🙋♂️ I’m personally left with two primary questions about everything in this section:
Who is this “observer” we keep referencing — this human who’s interpreting the model’s output and giving it a 👍 or 👎? Are they in-group or out-group? Are they smart or stupid? Are they really interested in the truth, or are they just trying to sculpt this model’s probability distributions to serve their own ends?
In cases where I’m lucky enough to be the observer who decides whether the model’s output is true or not, do I really always want the truth? If I ask the model for a comforting bedtime story about a unicorn, do I really want it to go all Neil deGrasse Tyson on me and open with “well actually, Jon…”? Isn’t the model’s ability to make things up often a feature, not a bug?
These questions are central to the issue of “hallucination,” but they are not technical questions. They are questions of philosophy of language, of hermeneutics, of politics, and, most of all, of power.
This really is the payoff to all this article’s talk of probability distributions, atomic orbitals, and alive/dead cats: When I, a human being with a history and an identity and a set of goals and interests, observe a single point in the model’s probability space, it’s always up to me to interpret that point as language and to imbue it with meaning.
Indeed, LLMs may be humanity’s first practical use for reader response theory, apart from academic self-promotion. Authorial intent doesn’t matter because there literally is no author and no intent — only a text object that a machine assembles from a vast, multidimensional probability distribution.
ChatGPT doesn’t think about you at all
The ChatGPT experience of back-and-forth interaction is powerful, but it’s really a kind of skeuomorphic UI affordance, like when a calculator app looks like a little physical calculator.
🗣️ It certainly feels like the model itself is learning about you just like you’re learning about it — like as the conversation develops you’re each updating your own internal understanding of the other. But this is mostly not what’s happening, and to the extent that it is happening, it’s happening in a very limited way.
There’s a final concept you need to grasp in order to thoroughly untangle yourself from the idea that ChatGPT is truly talking to you, vs. just shouting language-like symbol collections into the void: the token window.
How a pre-ChatGPT language model works
With a normal language model like what I’ve described so far in this article, you give the model a set of inputs, it does its probability things, and it gives you an output. The inputs are entered into the model’s token window.
Tokens are the ML term for the “symbols” I’ve been talking about in this whole article. I wanted to reduce the specialist lingo so I said “symbols,” but really the models take in tokens and spit out tokens.
The window is the number of tokens a model can ingest and turn into a sequence of related output tokens.
So when I use a pre-ChatGPT LLM, I put tokens into a token window, then the model returns a point in its latent space that’s located near the tokens I put in.
Let’s return to the diagram at the start of the article and look at it again with our new knowledge of token windows and probability distributions. That weird-looking thing in the middle is supposed to be the model:

🔑 This point is key: the probability space does not change shape in response to the tokens I put into the token window. The model’s weights remain static as I interact with it from one window to the other. It doesn’t remember the contents of previous token windows.
Think of it this way: Every time I put tokens into the model’s token window and hit “Submit,” it’s like I’m walking up to it on the street and speaking to it for the very first time. It has no place to store any mutually evolving, shared history with me.
Another analogy that’s not perfect, but it’s pretty close: Every time I feed a specific prompt and a seed into Stable Diffusion, I get back the same image. Each prompt and seed combination will take me to a single point in latent space where a particular image is located, and if I keep giving it the same input tokens I’ll keep getting the same output tokens. I’m not building up any shared history with the model and Stable Diffusion isn’t “learning” anything about me as I use it.
(Language models like GPT-3 purposefully inject randomness in places where Stable Diffusion does not, in order to vary the output and make it seem more natural. That’s why you get different responses to the same prompt from a language model — it’s a little bit like using Stable Diffusion but the software is forcing you to vary the seed number on each submission. It’s not exactly like that, but it’s close enough.)
🤏 The end result is that the only brand new, post-training information that the model can obtain about the world is limited to whatever I put into a token window. If I type a word sequence containing facts about my marital status into the token window, then the model takes those sequences and returns a point in latent space that’s adjacent to the input sequence — a point that probably represents facts that seem related to the facts I gave it in the token window.
ChatGPT’s one cool trick for faking a personality
ChatGPT is an LLM with a single, large token window, but it uses its token window in such a way as to make the experience of using the model feel more interactive, like a real conversation.
Warning: I haven’t read an explicit explanation of how it works, so what’s in this section is my informed speculation based on how it kinda has to work. There really aren’t any other options given how LLMs function, but as always if I’m wrong I’m happy to be corrected.
ChatGPT’s clever UI trick is easier to show than to describe, so let’s imagine that I open up my browser and start a fresh ChatGPT session that goes something like this:
Me: What’s up, man.
ChatGPT: Not much. What’s up with you?
Me: Eh, my cat just died in a lab accident.
ChatGPT: I’m very sorry to hear that.
Me: Yeah, it sucks. I’ve already picked out a dog at the shelter, though. I pick him up this afternoon.
ChatGPT: That’s exciting! I’m sure your new dog will be a as good a companion for you as your now deceased cat.
Let’s break this session down into multiple token windows, each of which gets fed into the model over the course of our session:
Token window 1:
{What's up, man.}Output 1:
{Not much. What’s up with you?}Token window 2:
{Me: What’s up, man.
ChatGPT: Not much. What’s up with you?
Me: Eh, my cat just died in a lab accident.}Output 2:
{I'm very sorry to hear that.}Token window 3:
{Me: What’s up, man.
ChatGPT: Not much. What’s up with you?
Me: Eh, my cat just died in a lab accident.
ChatGPT: I’m very sorry to hear that.
Me: Yeah, it sucks. I’ve already picked out a dog at
the shelter, though.}Output 3:
{That’s exciting! I’m sure your new dog will be a as good a companion for you as your now deceased cat.}🪄 Do you see the way it works? OpenAI keeps appending the output of each new exchange to the existing output so that the content of the token window grows as the exchange progresses.
Every time I hit “Send,” OpenAI is not only submitting my latest input to the model — it’s also adding to the token window all the previous exchanges in the session so that the model can take the whole “chat history” and use it to steer me toward the right lobe in its probability space.
In other words, as my ChatGPT session progresses, the “text prompt” I’m feeding this model is getting longer and more information-rich. So in that third exchange, the only reason ChatGPT “knows” my cat is dead and can respond appropriately is because OpenAI has secretly been slipping our entire “chat” history into every new token window.
The model, then, does not and cannot “know” anything about me other than what’s there in our chat history. The token window, then, is a form of shared, mutable state that the model and I are modifying together and that represents everything the model can possibly use to find a relevant word sequence to show me.
📝 To summarize:
Frozen and immutable during normal use: the model’s weights, which give rise to the probability distributions described above and that represent everything it “knows” about language and the world.
Can be updated with new facts about the world: the token window that I dump into the model in order to get fresh output from it.
Note that in the case of BingGPT, it seems there was probably an extra step in there where that newer model was doing a web search, then dumping the results into the token window alongside the entirety of the chat history.
🐳 If you’ve grasped all of the above, then you know why the 32K-token window on the upcoming versions of OpenAI’s models is a really big deal. That’s enough tokens to really load up the model with fresh facts, like customer service histories, book chapters or scripts, action sequences, and many other things.
As token windows get bigger, pre-trained models can “learn” more things on-the-fly. So watch for bigger token windows to unlock brand-new AI capabilities.
That was a really excellent description. I work in the space in the engine underpinnings (ML compilers for custom AI chips) and that fleshed out what I had guessed but hadn’t had time to fully investigate.
The rather fundamental problem with this "it's all just probabilities, and those words don't actually have any meaning to the model" take is that it can't explain this:
https://thegradient.pub/othello/
TL;DR: if you train a GPT model on a board game without explaining the rules (or even that it is a game) - just giving it valid moves and training to predict the next move - it turns out that this training process actually builds something inside the neural net that appears to be a representation of the game board; and twiddling bits in it actually changes what the model "thinks" the state of the game is. At this point, you could reasonably say that the trained model "understands" the game - what is understanding if not a mental model?
But if so, then why can't ChatGPT also have an internal model of the world based on its training data, above and beyond mere probabilities of words occurring next to each other? It would necessarily be a very simplified model, of course, since the real world is a lot more complex than Othello. But, however simple, it would still mean that "the model has a kind of internal, true/false orientation to the cat and different claims about its circumstances". And it would explain why it can actually perform tasks that require such modelling, which is something that requires a lot of "none of it is real, it just feels that way!" handwaving with a purely probabilistic approach.