
Doing Real Work With LLMs: How to Manage Context
Of roguelikes and grounding problems

The posts in this series are about prompt engineering, but they are not a summary of prompt engineering tricks from around the web. I have not read many prompt engineering guides, mainly because I’m too busy prompting for work, and most of them repeat the same stuff over and over again anyway. At any rate, I say this because while the posts in this series are about prompting and prompt engineering, all of their advice is fairly idiosyncratic to me and my experience. I could almost title these posts, “How to think about prompting like Jon Stokes.”
So if you’re looking for what Google thinks are prompt engineering best practices, you should read a Google guide. Same for OpenAI, Anthropic, etc. I am prompting models from all of these vendors regularly, so what I cover in these posts is a bit more “meta” than how to organize a prompt for a certain model, or what kind of language to use, and so on. I’m more interested in exploring how to think about working with LLMs than I am in specific tricks. Of course, I will include some practical examples and actionable tips, but the point of these posts is to formalize and share some ways of thinking about prompting that I’m personally finding useful at the moment.
“Models are only as good as the context we give them.” — Unknown Thinkfluencer
In the previous post, one of the main things I stressed was the importance of always breaking up work into bite-sized chunks to feed into an LLM. In this post, I want to expand on this point and go into some detail on why I think this is the case and what it means on a practical level for getting valuable outputs from LLMs.

LLMs as roguelikes: sessions & runs
A basic concept I find myself turning to recently when working with LLMs and when coaching users and engineers on how to work with them is that of the session.
Sessions are pretty much what they sound like: I sit down with an LLM to run a series of inferences that will hopefully result in some useful work.
A session has the following qualities:
It’s going to cost me some money, but I’m not sure how much upfront.
Success is uncertain, and in fact, even the criteria for success may not be well-defined when I start the session — I may actually kick off the session by trying to develop a set of criteria in partnership with the LLM.
I’m paying close attention to everything that happens, and I have the feeling of doing real work that is challenging (i.e., it’s very active, not passive).
It has the feeling of exploration, complete with a certain amount of backtracking or accidentally looping around to the same spot from a different entry point.
My main responsibility in the session is the management of the context window that I share with the bot (see below).
I tend to think of sessions as broken up into runs — I’ll start a run, and it may go for a while, but then I’ll just start all over again if I find I’ve gone down a blind alley. Or, I may start a session by trying to develop a PRD that outlines the work I need to get done, and then once the PRD is in good shape, it’s time for me to take that PRD as the starting point for another run.
Those of you who play roguelike games have probably already pattern-matched the language and concepts here. I basically treat LLM sessions as roguelike gaming sessions that cost money and time. When working with an LLM, I sometimes “die” and have to restart the level, but I don’t restart from scratch — I retain experience and sometimes even specific, valuable artifacts (in the form of Markdown files) from run to run.
The Markdown artifacts I develop over the course of a series of runs are how I manage state and shared context with the model as I explore the problem space during the session. It’s a bit like an exploration journal in a CRPG (ok, now I’m mixing gaming metaphors, but hopefully this is helpful).
But these Markdown artifacts aren’t just for me, though. Or they’re also for the LLM to use in future runs. There will be much more on this towards the end of the post, though.
The context window
Point number 5 in my list from the previous section is key, so I want to expand on it. My goal as the “player” in an LLM session is to constantly be curating and shaping the context that I’m sharing with the LLM. So let’s stop and look a bit more closely at what this context is and how it’s structured.
Most AI users in 2025 have some concept of the context window or token window (I tend to use these two terms interchangeably). In that earlier window, I described the token window as a piece of paper on which you and the model are recording your back-and-forth:
You write down a question,
the model reads your question on the paper and appends a reply,
then you append your own reply,
then the model looks at it and (not having any memory outside that scrap of paper) rereads the whole exchange and adds a new answer,
and on it goes.
The token window, then, consists of two main types of tokens:
The tokens you, the human, added to it
The tokens the bot added to it
Now we get to the most important concept I’m introducing in this post: I want to call the sequence of tokens that you, the human, have added to the token window the grounded sequence, and the sequence of tokens the model adds after reading your input tokens the ungrounded sequence.
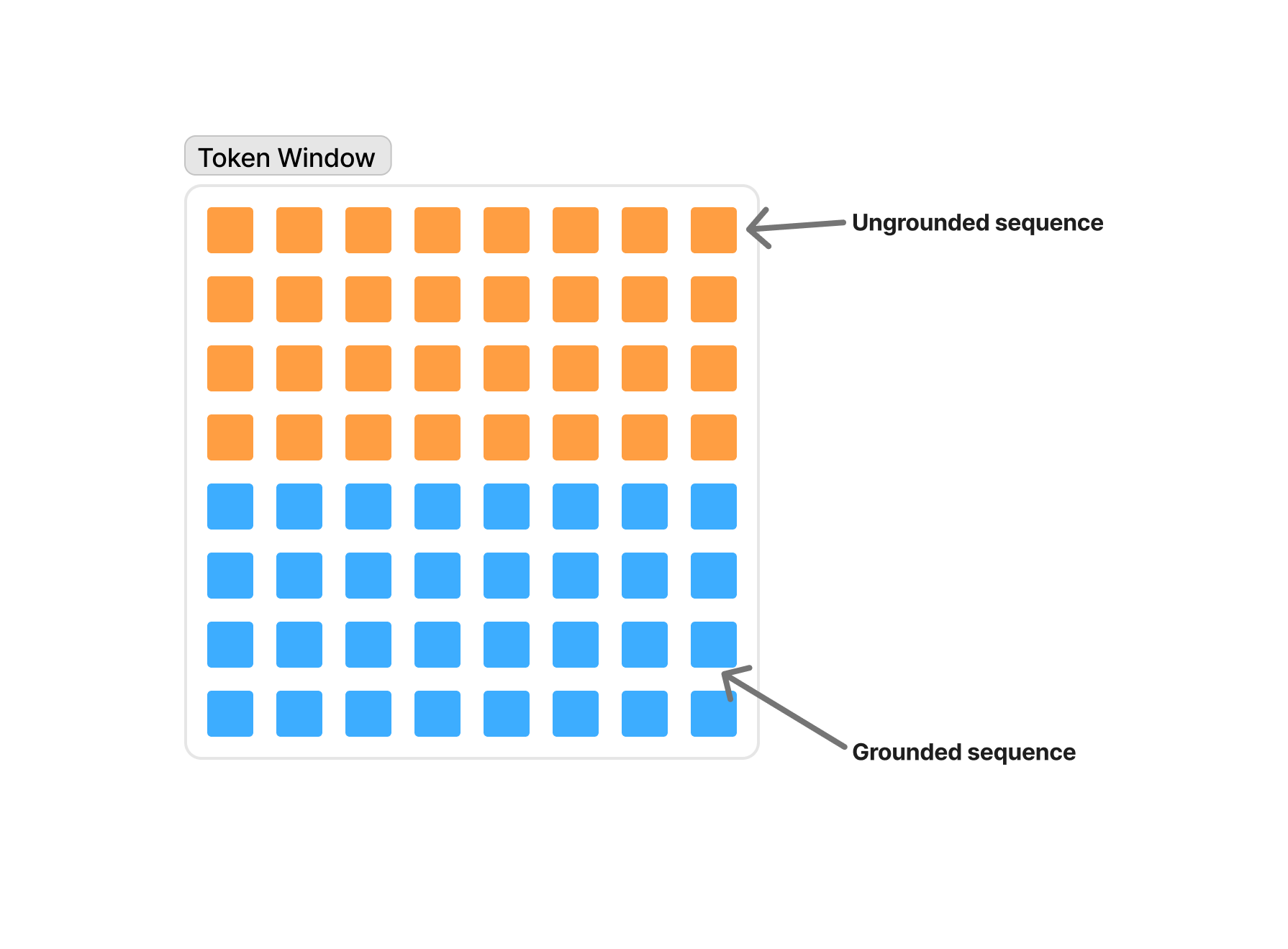
To understand the way this grounded vs. ungrounded sequence concept can help us with prompting, we have to take a little detour into an old and widely known problem in AI and the philosophy of mind and language.
The grounding problem
I’ve always loved Yeats’s classic meditation on aging as a poet — on getting high on his own intellectual and artistic fumes and then coming back down to earth and once again anchoring his work in that mundane, disorganized place that all the poet’s higher-order symbolism points back down to.
Heart mysteries there, and yet when all is said It was the dream itself enchanted me: Character isolated by a deed To engross the present and dominate memory. Players and painted stage took all my love And not those things that they were emblems of. Those masterful images because complete Grew in pure mind but out of what began? A mound of refuse or the sweepings of a street, Old kettles, old bottles, and a broken can, Old iron, old bones, old rags, that raving slut Who keeps the till. Now that my ladder's gone I must lie down where all the ladders start In the foul rag and bone shop of the heart.
I think Yeats would’ve intuitively understood the grounding problem. In a nutshell, the grounding problem is about how human language as a system of abstract symbols is connected to — or grounded in — the real world of physical interactions and sensory perception.
For a great example of a concept that’s so high up the ladder of abstraction and seems to be so purely about language itself, and to have no real touch points at all with the physical world of things, look no further than… well, the grounding problem itself.
I’m kind of joking, but I’m also not. Only a group of philosophers and linguists who have dwelled for so long together at the heights of abstraction would ever look down and ask themselves of the language they’re using: “How, exactly, are all these symbols we traffic in connected to something real and physical?”
It was thought for a long time, and is still thought in some AI hater circles where academic linguists and like characters are still deep in denial about recent LLM progress, that because they are trained solely on language, LLMs would never have an internal “world model” grounded enough in reality outside of language to actually be useful.
Probably the classic example of such thinking is the “octopus paper” by Emily Bender and Alexander Koller. (Bender is one of the foremost AI progress denialists.) I did a thread on that paper a while back, so I won’t go into it here:

The gist of the paper is that an LLM, not having any real first-hand experience of the world via some sensory input mechanism and being solely a stochastic process that produces ungrounded, language-shaped sequences, cannot truly reason about the world and solve problems in the world. (As I point out in the thread, the paper is so larded with caveats that I’m sure one of the authors could use one to dispute how I’ve characterized it just now, but whatever.)
All of this said, though, I do think the grounding problem is at least a little bit real, and it has real-world implications for working with LLMs.
✴️ Specifically, it is my experience that as the token window begins to fill with LLM-generated tokens, the ungrounded sequence that those tokens constitute begins to get further away from the region of latent space-time where our target sequence is located.
Aside: prompting is a search process
I want to reintroduce a concept that I’ve covered in the newsletter a few times and that I still find incredibly useful for thinking about prompting: inference is fundamentally a search process, where the user is trying to locate a useful sequence of symbols in the model’s latent space.
Much more on this concept here:
There’s also some related discussion in this post:
So when I’m prompting, I’m trying to locate a target sequence in the model’s latent space. Here are some examples of target sequences I might try to locate via prompting an LLM:
A good conclusion to an essay I’ve just written.
An explanation in plain, non-technical English of a difficult technical concept I’m wrestling with.
A unit test for a part of a computer program I’ve just written.
A part of a computer program for a unit test I’ve just written.
An image that can act as a suitable illustration for a point I’m trying to make in my newsletter.
You get the idea. Each one of the above things is a sequence of words or pixels. Any number of specific sequences might fight the bill — there may not be a single target sequence I’m after. But our intuition tells us that all the sequences that will work for our task are probably clustered pretty closely together in latent space, so in order to find them, we’ll need to prompt our way into the region of latent space where these related sequences are all located.
The best way to prompt your way into a region of latent space that contains your target sequence — maybe we can refer to this as the target region of latent space — is to start as near that region as you can.
If I want to prompt my way into a good concluding sequence of words for my essay, I should probably use the full text of my essay as my starting prompt, instead of, say, a generic sequence of words like, “Hey chatbot, I wrote an essay and I need a killer conclusion. Any ideas?”
💡 The intuition is that the sequence of words that constitutes my essay is located in latent space very near to a set of sequences that I would interpret as ideal conclusions for it. So by starting near these sequences, I’m increasing my odds of coming across them as I build the context window by going back and forth with the model over the course of a session.
🔑 Here’s the key insight: It’s more productive for me to imagine I’m searching for a concluding sentence to my essay than it is for me to imagine I’m requesting that a powerful Djinn summon a conclusion for me. The former approach leads to far better results than the latter.
If I’m thinking about prompting specifically as a type of similarity search — I’m using the LLM to locate the texts that are related somehow to the text I’ve provided as input — then this encourages me to think in the right way about the richness and relevance of the context I provide the model.
Context, again
To return to the topic of context, “context is king” is a phrase you’ll hear in AI circles. When people say this, they’re usually referring to the context we feed the model, but it’s important to grasp that in the course of an inference, the model is adding tokens to its own context. So, the model gets a vote on what is included in the context.
1️⃣ . Your job is to keep the context grounded in the world knowledge and domain-specific knowledge that you’re bringing to the session. The more the context stays dominated by grounded sequences throughout an LLM session, the more likely you’ll be to iterate your way into the target region of latent space during the session.
2️⃣. Conversely, the more the context becomes dominated by ungrounded sequences, the less likely the model is to ultimately converge on a valuable target sequence in the course of the session.
Keep reading with a 7-day free trial
Subscribe to jonstokes.com to keep reading this post and get 7 days of free access to the full post archives.