
Here’s What It Would Take To Slow or Stop AI
Everyone should be clear about what they're asking for when they propose to put a stop to all this.


The story so far: I haven’t seen this many people this confused about the basics of a technology this important since the rise of the internet in the late 90s. The more the legacy media starts looking at recent developments in machine learning the more impractical think pieces I’m seeing on the timeline from writers who don’t understand how any of this works.
Probably the most common genre of bad AI take is, “maybe we should press pause on AI development until we figure all this out.” There are two types of people who float this idea:
Those who have no clue what they’re actually asking for, because they either don’t know enough about AI or they don’t know enough about the way the world works outside of computers.
Those who know exactly what their suggestion implies, but think it’s preferable to whatever AGI doom scenario they envision as the alternative.
I’ve written this post for people who, for whatever reason of ignorance about machine learning or cluelessness about offline reality, find themselves in the first camp, above.
As for the people in the second camp, I respect them because they already know everything I’m about to say but are forging ahead anyway. I generally have a lot of respect for informed, true believers who have counted the cost and decided to commit to the hard thing, anyway. But I am prepared to die on the hill of opposing them.
Training, inference, and costs
The key to understanding what’s at stake in the “deliberately pause or slow down AI development” discussion lies in an appreciation of how machine learning’s costs and capabilities are distributed across the computing landscape.
I use the following slide in my talks about machine learning, and it describes the main phases of machine learning in the order in which they occur:
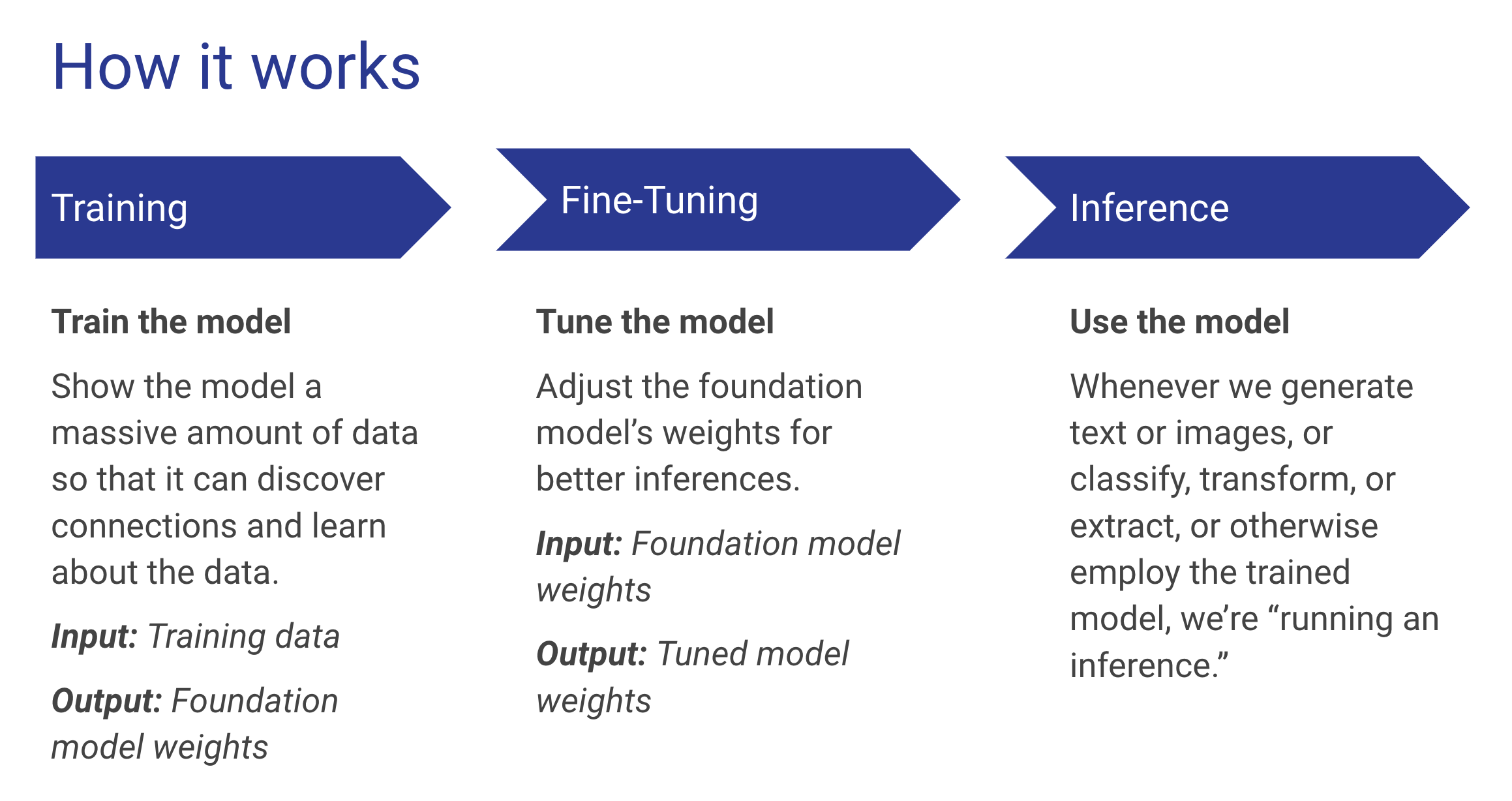
You first train a model, then you do any fine-tuning and tweaking to finish setting the model’s weights. Once the weights are set, you can use them to run inferences (or predictions, a more common term in generative AI circles).
Here are the two main phases — training and inference — illustrated using some numbers from Stable Diffusion:

You can see that the training process takes a massive 240GB dataset and throws thousands of hours of GPU time at it in order to train a model file that ends up being around 4GB in size. Anyone who has the resulting Stable Diffusion model file can then use it to run an inference on a single GPU.
There are important differences in cost between training and inference, and these differences have crucial implications for any plans to stop, pause, or otherwise control the development of AI:
🏋️ Training is a large, fixed, up-front expense. It can easily run into the tens of millions of dollars to train a model like Stable Diffusion or GPT-3. This cost is borne by whatever party is doing the training (OpenAI, StabilityAI, or whoever is creating the foundation model). But once the model is trained and you have the model file, then that particular cost is now sunk.
🧠 Inference is an unbounded collection of ongoing expenses that can and usually do outstrip the cost of training pretty quickly. However, the impact of inference costs on any one party’s bottom line depends on who us using the trained model and to what end.
🔒 For a proprietary model like the one that powers ChatGPT, there’s only one company (OpenAI) running inferences on the model so that company bears the whole expense of the inference phase. (This is why ChatGPT had to start charging when ChatGPT got too popular — the inference costs were eating them alive.)
📖 For an open-source model that anyone can run, like Stable Diffusion, all the GPUs that run the inferences are owned by different users and companies (each of whom is in possession of a copy of the trained model file). So the cost of the inference phases is distributed across the user base.
That second bullet point above is why decentralized AI would be quite difficult to completely stamp out. Open-source model files are already out there in the wild, and the number of them is growing.
Stable Diffusion is the original, high-profile open-source LLM
There are near-GPT-3-class models already out there that are now available for use, like GPT-J.
Stability AI is rumored to be working on an open-source ChatGPT clone that may be better than ChatGPT.
Meta’s major new foundation model, LLaMA, has been leaked into the wild.
Sites like Hugging Face, Civitai, and Replicate are already hosting thousands of open-source models and variants of models, and that number will grow as more models are either released or leaked.
Regarding Meta’s LLaMA, the leaked archive has multiple models, one of which is a 7-billion parameter model that can be run on a single, consumer-level GPU. So if I had the right high-end gaming rig, I could run inferences on the state-of-the-art LLaMA model from my home.
The main points of control for AI
🛑 To stop or pause the development of AI and/or to restrict its use, there are three main points of control:
The training phase requires large, coordinated pools of GPU power, so you could attack AI in this phase by trying to restrict access to GPUs.
Model files could be treated like digital contraband — spam, malware, child porn, 3D printed gun files — and purged from the major tech platforms by informal agreement. (We probably wouldn’t need to pass new laws for this. Just some phone calls and letters from the feds would do the trick.)
The inference phase requires GPU power, so consumer access to GPUs could be restricted.
Let’s look at each possible point of control in more detail.
Training restrictions
🚦 In order for anti-AI activists and regulators to successfully shut down or restrict the world’s ability to train new models, governments would have to restrict consumer sales of high-end gaming GPUs. If consumers retain access to GPU power, they might network their hardware together using a distributed training platform and train models in an open-source, cooperative fashion (think Folding@Home, but for training models).
Companies would also need their access to GPUs controlled to prevent them from either training models themselves or renting GPU hours out to others for training. They wouldn’t be able to purchase the hardware or rent it in the cloud without some kind of authorization from the government, and some monitoring to ensure that they’re not training models with it.
🤗 Certainly, the Pentagon, the NSA, the CCP, the EU, and other state actors would be pretty happy to not have to compete with consumers and businesses for access to leading-edge GPU hardware. Those state actors would keep training models, whether it’s nominally legal or not. (If anyone suggests to you that outlawing AI would prevent the US security apparatus from continuing to train new models and advance the state-of-the-art, then that person is a lying fed. We all know that warrantless domestic surveillance was wildly illegal yet it was done anyway.)
Model file restrictions
As I’ve pointed out a few times on Twitter, even if we were to stop training new models and focus solely on commercializing the models that have already been developed, those models are so powerful and their potential so untapped that an astounding amount of disruption will be unleashed as millions of developers and hundreds of billions of investment capital find ways to commercialize them.
It’s also the case that the vast majority of the disruption, disinformation, and deep-fake types of scenarios that certain people are currently flipping out about can and will be enabled by the models listed above that are already out there in the wild.
💣 So to really stop AI, you’d not only have to halt all model training, but you’d also have to nuke all the model files from the internet and from everyone’s hard drives.
You could surely keep most people from accessing model files by getting a few large tech platforms to agree to treat those files as digital contraband — basically, the same treatment they give porn, spam, and malware. This is something I’m actually very worried about, because if (or when) that happens, then here’s who will have access to the models that are currently available to the general public:
The Russian bad guys who feature in these AI-powered disinformation and deep fake doomsday scenarios
Disney, Google, Meta, Microsoft, Amazon, the US government, the CCP, and other large, powerful incumbents
Programmers and researchers in Asia, Africa, and Latin America who are just as smart as the US and Europeans and who can and will build on existing models and train new ones, thereby creating trillions of dollars in value as they (and not us) bring the next generation of AI-powered software to market.
🫵 I suspect most of the technocrats currently talking up the idea of “pressing pause” on AI are aware of everything I’m saying here and would actually be ok with Russian bad guys and large corporations having access to this tech as long as the problematic masses can’t get their hands on it. They really just hate you and want you to stop typing stuff they disagree with into places where anyone can see it. The dreaded Russian troll farms are a convenient person of bogey — the real enemy is the average oldthinker who unbellyfeels Ingsoc.
However, I do wonder if these types have really thought through the fact that regions outside the US and EU will not be stopped or even slowed appreciably by whatever tyrannical AI restrictions we pass.
Inference phase restrictions
Killing AI by stopping inferences would require essentially the same set of limitations as listed above for the training phase. You’d need to restrict consumer and business access to GPU hardware.
And again, all governments would just eat this up. More cheap chips for them, and more centralized power and control.
Distribution and redistribution
🚔 It should be clear at this point that AI will not be stopped or even paused — certainly not globally — by anything short of a globally coordinated totalitarian crackdown that involves all governments acting in concert. This seems unlikely, and to the extent that it’s possible it’s actually a far worse outcome than unrestricted AI for everyone.
What’s more likely, at least in the west, is that restrictions on machine learning will cause progress in AI to be redistributed, along with the social benefits and wealth that flow from that progress.
🇺🇸 🇪🇺 If some or all of the measures described here were enacted in the US and Europe, then internally to these two regions the startup scene and the general public would lose access to AI, but the tech would remain in deep-pocketed public and private sector hands, and in criminal hands.
🌏 Externally to the US and Europe, the rest of the world would love the drop in the prices of GPUs and the de facto monopoly we’d be giving them on AI innovation and commercialization of machine learning. This would be a huge boost for them, as they’d end up selling this software to us via VPNs anyway.

🩺 When a really high-quality medical diagnosis AI is deployed in Africa, do you really think US citizens are not going to upload photos of their bumps, scrapes, and scans into it to get low-cost, ML-powered medical care? Maybe our government tries to build the US version of China’s Great Firewall to keep us out, but we’ll just use VPNs.
I know he’s a controversial figure, but I have a ton of respect for Eliezer Yudkowsky because he knows everything I’m saying here and is not kidding himself or anyone else about any of it.
Unlike most of the other grasping, clout-chasing hacks who are de facto advocating to bring tyranny and relative poverty to our shores with their calls for constitution-busting restrictions on who can own what hardware and have what files, Yudkowsky and many of his rationalist and Effective Altruist fellow travelers are up-front about the fact that the only thing that can stop AI is an ultra-powerful one-world government with a stunning amount of control over what 8 billion people can and cannot do with all the computers we’ve made.
Update March 7, 2023 @ 4:28pm CT: Some people responding to this on Twitter and in other places don’t seem aware of my own views on AI risks, which makes sense because while I reference them in asides here I don’t explicitly lay them out. So let me quickly summarize my position, just for clarity’s sake:
I am not convinced by existential risk arguments about AI.
I also don’t have much use for arguments that amount to, “the bots will say the naughty words” or “bad guys will suddenly be very eloquent and convincing, and civilization will disintegrate as the masses are led astray by Russian trolls.”
I do believe that AI is disruptive and will break our society in many unexpected ways that will cause some amount of chaos. It will get nuts, but we will make it through.
One day in the future, we will look back on an incredibly disruptive era when many things were turned upside down by rapid advances in AI, and we will say that while there were some big winners and big losers, on the whole, it was a strong net positive for humanity.
I could be totally wrong about all of the above, and AI could be either maximally bad or an unqualified good. The error bars are very wide (or the tails are very fat, or whatever metaphor you want to use here).
What about Taiwan?
🇨🇳 One way to slow down AI innovation would be for China to invade Taiwan and take TSMC offline. However, the impact of such a development is quite a bit more complicated than a simple halt to AI progress.
Throwing increasing amounts of GPU power and data at deep learning models has yielded incredible results, and no one yet knows when we’ll reach the limits of scaling. But as console game developers know, you can still scale performance on fixed hardware by finding performance optimizations.
There are surely many optimizations in both the training and inference phases that have gone undiscovered for various reasons:
Money has been so cheap that it’s easier to throw hardware at the problem
There hasn’t been enough downward market pressure on inference and/or training costs
There hasn’t been enough labor market pressure pushing some critical mass of skilled programmers into developing core ML tech
All of the above is changing, though. Money is getting more expensive with rising rates, and ML’s commercialization — especially when it’s driven by open-source models — is creating new markets for training and inference performance. It’s also the case that startups like Replit and PlaygroundAI are actively hiring coders to innovate in core ML research.
☄️ Ultimately, most of the slowdown in AI development that would occur after TSMC goes dark would probably be caused by collateral damage to the economy, supply chains, and social cohesion. It’ll be hard to move AI forward if we’re in an instant Great Depression 2.0 and there are food riots, rolling blackouts, and whatever else is in store post-Taiwan invasion.
Postscript: Guns and AI
Americans who’ve followed our national gun debates will recognize many of the arguments and warnings presented here about AI as having close counterparts in the gun control wars.
This is a productive way to think about this fight, and I endorse it. The gun control wars and the AI wars can mutually illuminate one another other. I realize many of you will flinch at this because our gun control debates are notoriously terrible and circular, but in recent weeks I’ve come to believe that they’re not nearly as bad as the AI wars are shaping up to be. If the AI wars are merely as toxic and unproductive as American gun control discourse, that would be a win.
👉 By way of encouraging people to mine the gun control fight for analogies, here’s how you should think about the current state of play in AI: Imagine that with a single software download, any laptop or smartphone on the planet could be turned into a loaded 9mm pistol.
What would it take to institute a global gun control regime in such a world, where there are already billions of such devices in peoples’ hands, and they’re unregistered and currently untraceable?
Think about gun control approaches that involve things like:
Biometric locks
Registration requirements
Background checks
Confiscation
Restrictions on timing or quantities of purchases
Routine home or business inspections
These are exactly the kinds of things you’d need to entertain as part of a global effort to stop the open-source AI that’s already out there right now. So as you think about governments deliberately stopping or slowing AI development and commercialization, think about how you’d need to implement most or all of the above in every country in the world.
⚔️ If you do that thought experiment, and you’re still in the “stop AI” camp, then I wish you good fortune in the wars to come.
A couple of suggestions for your first ("How it works") slide. The first step is to collect and curate training data. You don't just snap your fingers and have it magically appear. In the second (now third) stage (fine tuning) you left out a crucial input: human judgement, which you need to source and vet. For inference, the inputs are the tuned model weights and some sort of prompt (i.e., compared to the earlier stages, inference doesn't work in a vaccuum).
Really good article, I agree on almost all of the reasons for why it would be hard (I don't exactly reach the same conclusion about where we end up, because there are countermeasures, and specific policies we can do which reduce risk from AI in the phase where it's only accessible to large companies and not all, and it's possible to scale up over time to centralized regulation).
I like your last analogy.
If you were deeply convinced there was a >5% chance that in 10 years any computer could with a download become a new unique pandemic virus, I assume you'd be on board with centralizing and limiting access ? (Or is that sacred and there is no amount of believed risk which would warrant control of compute?)
Your world model seems good and your arguments are good so I'd be interested to discuss where you leave the boat for the object level conversation of "In the current trajectory, AI systems will proliferate and become more and more capable, while our capacity for control will lag behind, until a takeover happens and humanity is forever disempowered". You can find a list of specific threat scenarios summaries made by the Deepmind team here if you want some specifics of what could go wrong : https://www.lesswrong.com/posts/wnnkD6P2k2TfHnNmt/threat-model-literature-review
If when reading them you find yourself having compelling counter arguments for why that can't happen and it's still better to accelerate than to try to minimize those risks, I'd love to hear about it!