


How to Do Real Work With LLMs, Part 1
3D flight simulators and Turing tests are cool, but some of us have real work to do

Housekeeping: After a long hiatus, the newsletter has returned. I’ve been building in generative AI for the past 18 months, working closely with every model release and solving real customer problems with LLMs. I’ve learned a ton about how to do productive work with LLMs, and I’m going to start sharing that in this rebooted newsletter.
Some posts will focus more on the theory of getting work done with AI, while others will feature prompts that I use in the real world for real work with Claude Code, Cursor, and even my own tool — Symbolic AI.
“This model has only been out for 24 hours. Here are 11 wild things that will blow your mind. A 🧵”
We’ve all scrolled through the demos in this kind of X thread, then closed the tab and gone back to our day jobs. The videos and links are usually impressive — sometimes they’re even scary — but rarely does any of the wizardry on display seem to have direct implications for the real work that we have to do in the course of our day.
The feeling we often get from such demo dumps is something like, “Yikes, if I were in the business of making 3D flight simulators in a browser, or passing Turing tests, or creating GIF animations in a particular style, I would be rendered unemployed and unemployable by this. Glad I don’t do any of that for money! But one day I’m going to be in big trouble, aren’t I?”

I’ve been working in gen AI for a year and half now, going all-out to use every state-of-the-art model release for real-world customer tasks of the exact kinds that these models are supposed too be better-than-human at — writing news stories, press releases, blog posts, newsletters, and similar texts for sophisticated human readers and editors. So I can report from the front lines with some confidence: the picture is a lot more complicated than these demo threads suggest.
👉 Here is the deep secret of autoregressive LLMs in the current moment, a secret that will wreck many fortunes even as it makes a handful of others: All generative AI outputs are just demos.

I’m serious about this — the AI haters are sort of right, at least on this narrow point. Gen AI is flashy demos all the way down. There is nothing outside the flashy demo. Every time you prompt a SoTA LLM, the output you get back is a mini Truman Show, and you, the user, are the star of it. Every one of those AI thinkfluencer threads are just clips of other people’s Truman Shows.
💰 But there’s a second part to the above claim, which I left out but that makes all the difference, especially for those of us who are using gen AI for work. Here’s the claim its full form: All generative AI outputs are just demos, but some demos are useful.
The art of doing real work with gen AI is the art of rapidly cycling through a series of tiny little useful demos, and at some point taking a step back from that process and recognizing that you’ve demo’d your way into a valuable solution for a real problem.
Fake it till you make it
Ok, so what does it mean to “rapidly cycle through a series of tiny little useful demos”, and how do you actually solve problems this way?
First, let’s unpack the term “demo.” What’s a demo in the software sense? I think a useful definition of a software demo, at least for our purposes here, is something like the following:
A software demo is when you set up a specific problem scenario that you know for sure your software can win at, and you carefully stage-manage and orchestrate all of the inputs so that you get the most impressive possible output when you run that scenario live (usually for an audience).
The canonical demo example is Steve Jobs unveiling the first iPhone. This was a high-stakes exercise before global audience, and it was rigged, rehearsed, choreographed, and even faked down to the last detail, so that the phone would look maximally impressive. Nothing was left to chance. All constraints and parameters and inputs and possible outputs were taken into account before demo day, so that when the time came to execute, the product appeared to nail it.
All of this stuff I just said about the Jobs iPhone demo — how everything was teed up perfectly, and nothing was left to chance — is key to getting economically valuable results from an LLM.
⭐️ Note that qualifier: economically valuable.
If you’re just trying to produce something amusing or impressive, you can quite often lazily one-shot an LLM into giving you an output that scratches the itch of, “I want to see the computer do something ✨ magical✨ just for me.” That’s because a lot of money and electricity goes into training the models to produce exactly that magical, just-for-me feeling in users who are doing low-effort, low-reward types of activities.
But to get a legitimately valuable result from a model takes a lot more work and expertise than the basic “magical chatbot” experience leads us all to believe. You have to be willing to commit to a level of effort that’s commensurate with the value of the problem you’re trying to solve via LLM, and you also have to know where the tradeoff point is between prompting your way into a solution vs. just doing it all yourself.
💡 This is a heuristic that I use and would recommend to you: The value of an LLM output scales with the quality of the input context, and the scaling function is sigmoid.
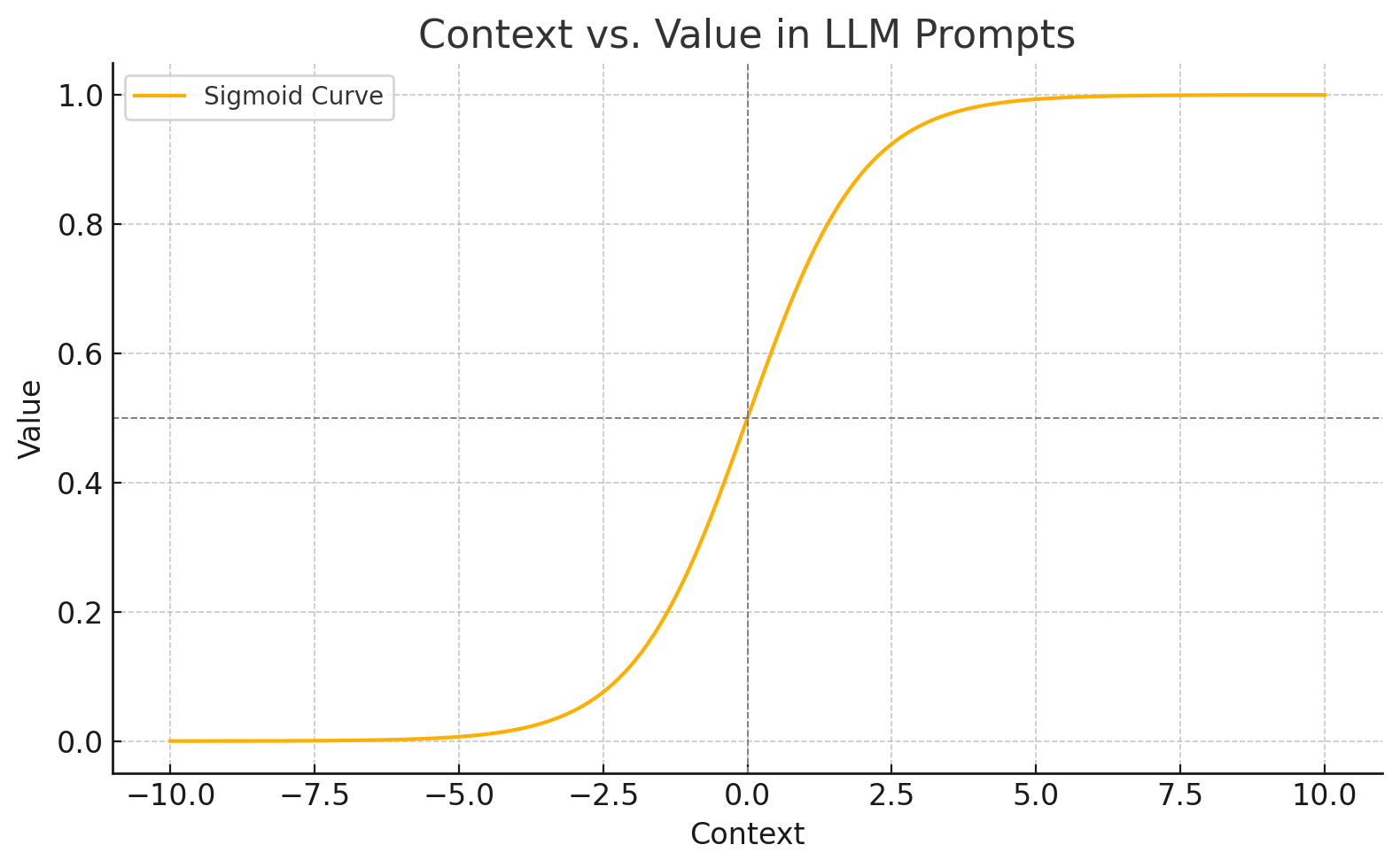
You want to be prompting your way into the top bend of that curve, and to hit eject before you reach the region of rapidly diminishing returns.
Again, prompting an LLM is very much like prepping a high-stakes demo every single time. You go into an LLM session thinking about all the tiny little ways you can maximize your odds of success and minimize your odds of failure — will full knowledge of the corner cases and outliers and happy paths and sad paths — because the more work you put in up-front, the higher your odds of a valuable outcome when you hit “send” and start spending on GPU cycles.
The other way to think about the context vs. value relationship in prompting is that the more novel the task — the further outside the LLM’s training data it is — the more high-quality context you, the human, will have to bring to the LLM to get the result you want.
If you’re trying to write a formal letter of introduction, you won’t need to bring very much to your prompt other than the basic facts about the two parties you’re introducing. The models have seen tons of such letters and guides for writing them in training, so you can just give it some basics and let it rip.
If you’re trying to finish the final book in your unpublished cryptid romance trilogy, then you’re going to have to find some way to give the LLM as much context as you can about everything that has happened in the first two books, plus all the backstory from your notes.
So the further out of the training data distribution you’re trying to push the LLM, the stronger and richer your prompt must be in terms of the classic kinds of PRD drafting that powers most serious projects.
So at the low end of the sigmoid curve is the classic “magic” AI demo experience, where you give the bot a simple prompt, and it thought of everything for you and did it exactly the way you didn’t even really know you had wanted it done. But there’s rarely much value here.
At the other extreme end of this curve, you’ll be doing just as much real work as if you had not used an LLM, but maybe the LLM has saved you some typing and other drudgery and given you incremental speed gains.
Eating the world, one bite at a time
You’ve probably read Marc Andreessen’s famous essay, Why software is eating the world. In the 14 years since this was published, software has indeed eaten the world. In the Before Times, there was a whole universe of economically valuable labor that was being done in some physical, non-software-involved way, that has since transitioned either in part or in whole to the world of bits and bytes and networked computers. Matchmaking, grocery shopping, office meetings, music listening, party invites… You get the idea because you live in the same software-eaten world that I do.
Each of the startups behind the examples in my list started as a essentially a demo — a cardboard-and-duct-tape proof-of-concept created by a small team to validate a hypothesis about the market. These teams found initial signs of validation, then they iterated in the direction of that validation by building out their software to solve the business problems they were uncovering as they went.
LLMs are the next phase of this exact same phenomenon. LLMs enable human language to eat the software that is still eating the world.

The fundamental mechanism of testing and validating a hypothesis, then iterating in the direction of that validation, still holds in the world of gen AI. LLMs just enable us to go directly from words to proof-of-concept, then from proof-of-concept to production via more words, and to do this rapid cycling for impossibly small and niche problems many times an hour if we need to.
Some examples of such tiny problems that we can solve with an LLM quickly and that can aggregate into one large solution:
How can I add some supporting data from my notes to the above paragraph? I need facts and figures to really drive this point home.
How can I refactor this code module to make it more readable?
What are quotes in this hour-long transcript that are relevant to the article I’m working on right now?
How can I get these fifteen links summarized and organized into our standard newsletter format for our drip campaign?
How can I rewrite this paragraph into a bullet list of points without retyping the whole thing myself?
Every one of the above micro-tasks is something we can describe in words more quickly than we can actually do it, and when it’s done correctly for our project, we’ll know it when we see it. Gen AI lets us quickly cycle through variants on any of the above tasks until we spot the one that works, and then accept that and move on to the next task.
As we move iteratively in small steps through a large piece of work with this repetitive motion of prompting → evaluating output → possibly re-rolling or tweaking → accepting, we can step back in from an LLM session and realize that we’ve gotten through work that would’ve taken us hours without AI in maybe tens of minutes or less.
There’s an old saying that applies here: “How do you eat an elephant? One bite at a time.” AI lets knowledge workers eat the whole elephant really, really quickly by taking it in small bites and flying through each bite in moments.
Note: There are very deep, information-theory-related reasons why the “small bites” approach is key for the present generation of autoregressive LLMs, and I hope to get to those in another newsletter soon. I have a draft on this, so we’ll see how it shapes up. But just note that this “small bites” strategy is not going away any time soon, and if you only get one thing from this post, then “always use small bites” may well be the most important and actionable.
Three rules for getting valuable outputs from LLMs
So far in this post, there has been a lot of theory and high-level advice. I’m not going to get into specific examples of prompts in this post — that’ll come in a followup. But I do want to get a bit more practical by boiling down everything I’ve said so far into three core rules for creating valuable prompts that do real work. Then, I’ll elaborate on each rule.
Keep reading with a 7-day free trial
Subscribe to jonstokes.com to keep reading this post and get 7 days of free access to the full post archives.