


Machine Learning And Deflationary Contagions
We're all gonna catch this, eventually.


Here’s the most common question I get from members of the press, analysts, and others I talk to about generative AI: can you describe what impact this will have on my industry?
Of course, this is the obvious question to ask, right? So I get it all the time, and because I get it all the time I’ve developed a standard high-level answer to it that I’ll share here so that in the future I can just summarize it and then send the questioner a link.
But before I get into it, note that I said “high-level answer.” That’s because there are two ways to answer this question:
What’s the underlying dynamic or force that generative AI brings to bear on certain types of human activity?
How will that dynamic or force affect the specific type of human activity I care about (e.g., journalism, software development, law, medicine, etc.)?
I’ll focus on answering question #1 in this piece because that’s how I always set up the answer to #2, which is the answer my audience usually cares about.
As with most people who are trying to answer the big-picture question, I’m focused on the relationship between machine learning, productivity, and deflation. But I answer this in a fairly specific way.
Here’s my core thesis on a dynamic that will come to govern large portions of the economy in a fairly short span of time: Software is a contagion vector through which the ongoing deflation in transistor prices can be transmitted to new parts of the economy; machine learning is a new and much more powerful and flexible version of that contagion vector that can reach new hosts.
To unpack that a bit further:
Every time software eats another part of the world, that part of the world is now exposed to the deflationary force of Moore’s Law.
Insofar as machine learning is a brand new category of software, it’s also a new vector of contagion for Moore’s Law-driven deflation.
Many creative forms of labor are situated higher up the value chain and have thus far had a large measure of immunity to software-mediated deflation. But with machine learning in general and generative AI in particular, much higher-value labor suddenly has no immunity and will get the full deflationary effect all at once.
Covid metaphors are lame, but if I were going to make one then I’d call generative AI software’s Omicron variant — immune escape + extreme transmissibility = everyone’s labor will finally catch the deflation bug, even the previously immune.
Moore’s Law and deflation
For those of you who are used to thinking of Moore’s Law in terms of transistor size or even computer performance, which is how it’s typically presented, you may not be aware that Gordon Moore originally formulated this idea in terms of deflation in the cost of transistors.
When Moore published his famous paper [PDF] in 1965 — the paper that’s cited as the origin of “Moore’s Law” — he was thinking not about increased “computing power” or “performance” but about lowering the cost of circuitry and about the impact such deflation would have on society. He writes:
Integrated electronics will make electronic techniques more generally available throughout all of society, performing many functions that presently are done inadequately by other techniques or not done at all. The principal advantages will be lower costs and greatly simplified design payoffs from a ready supply of low-cost functional packages. [Emphasis added]
You can see this deflationary dynamic spelled out in the graph below from Moore’s famous 1965 paper, which illustrates how he expected the relative cost per transistor to decline as transistors got smaller and you could pack more of them onto a single integrated circuit:
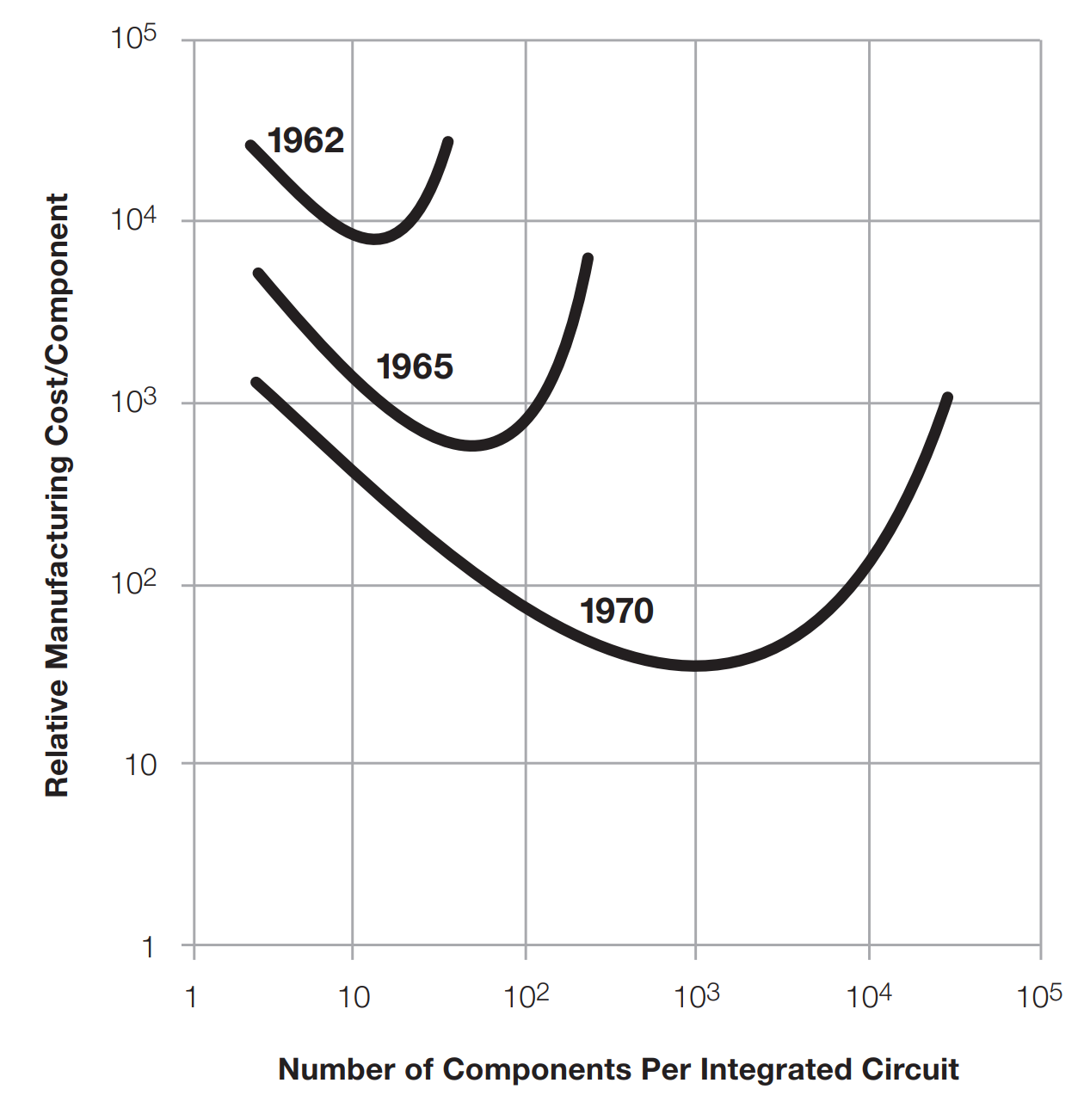
Here’s the part of the paper that comes closest to the way the law has been framed in popular lore:
The complexity for minimum component costs has increased at a rate of roughly a factor of two per year (see graph on next page). Certainly over the short term this rate can be expected to continue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000.
In his paper, Moore explained that he could at that time put about 50 transistors on a chip at minimum cost. He then extrapolated out to a then-hypothetical world of 1975 when his company would be able to cheaply cramp 65,000 transistors onto a single chip — about three orders of magnitude cheaper on a per-transistor basis than the cost of transistors in 1965. For a modern reference point, the Apple M2 chip has 20 billion transistors.
To go from less than one hundred transistors per chip to the tens of billions per chip, even if we factored in a conservative ~100X increase in the cost per chip, is a stunning quantity of deflation in a mere sixty-year timespan.
How, then, do you put all that deflation to work for you in some area of work or industry where you’d like to lower costs? The answer to this required a second innovation: software.
From hardware to software to models
Instead of designing special-purpose circuits to fit specific tasks, the semiconductor industry quickly discovered that it could design general-purpose circuits that could be applied to a wide variety of tasks. You adapt the general-purpose circuit to a particular task by feeding it an ordered sequence of instructions that can manipulate it into doing the work you need to be done.
The result of this software innovation was that any work that could be described as an ordered sequence of mathematical operations could now directly benefit from Moore’s Law’s deflationary effects. That work could piggyback on Moore’s deflationary curves so that as transistors get cheaper the work gets cheaper.
Humanity has had a pretty spectacular, multi-decade run of finding creative ways to turn ever newer types of labor into ordered sequences of mathematical operations. The following formula has been stunningly successful:
Identify a task to be automated.
Describe that task in computer code.
Run the code on a computer.
Iteratively improve the code + run it on cheaper and/or more powerful computers.
Deflation!
But there are limits to this approach, the most glaring of which is that it’s not always easy or even possible to render every kind of work we want to do as an ordered instruction sequence.
Machine learning as a software category gives us the capability to implement a new formula for producing software:
Identify a task to be automated.
Define an objective function and assemble some training data.
Use the objective function and training data to train a piece of software (called a “model” and written using the legacy software formula described above) to do the task.
Iteratively improve the objective function and training data + run the model on cheaper and/or more powerful computers.
Deflation!
In machine learning, #2 is where the limits are right now, but that’s a topic for another day. While ML researchers are working on mitigating or even eliminating the problems posed by finding the right objective function or curating training data, the rest of the software development ecosystem will be busy exposing many new categories of labor to the full force of the past sixty years of transistor deflation before we run up against the limits of #2.
Case study: the business of writing and publishing
I like the chart below because it’s a useful illustration of how the relentless drop in the cost of computing power has affected different parts of the economy to very different degrees, with some areas being very well insulated from tech-driven deflationary forces.



In the case of the top half of the above chart, the insulating factor is probably government subsidy, as Balaji points out in the tweet. But there are other parts of the economy where the full impact of the collapse in transistor prices isn’t felt simply because software hasn’t yet touched the higher parts of the value chain.
What does it look like when software moves up the value chain, from lower-level types of labor to higher-level, higher-impact types with greater value added? To find out, let’s examine an area I know really well: writing and publishing.
The following types of labor typically go into the production of a finished, written document that someone like myself publishes for public consumption:
Typing on a keyboard
Research
Creative synthesis of research into new ideas, insights, questions
Organization of ideas and notes into a draft
Revisions
Content edits (i.e., high-level changes to organization)
Line edits (i.e., improving style and diction)
Copy edits (i.e., fixing typos and grammatical mistakes)
Production
Font and layout choices
Art and figures
The above list is roughly in-order, but many of the steps are iterative and circular such that doing a bit of one step may lead you back to a previous step. Also, all these steps involve typing.
Now, the thing about typing is that “typist” used to be an entire profession unto itself, even within my lifetime (I was born in the mid-70s). But outside of a few narrow instances (like court stenography), software has eaten “typing” as a separate profession via the GUI and the word processor. And speech-to-text is poised to further diminish the importance of “typing on a keyboard” as a common task that we all learn to do and develop into a skill in the course of (white-collar) life.


Spell-checking and grammar-checking software have been chipping away at the cost of line and copy edits for all of my adult life, and now this is all getting an even more dramatic boost from ML-powered apps like Grammarly.
Under the “Production” heading, the profession of typesetting has also taken a massive hit from the GUI + word processor combo, since we all do most of this work, ourselves. But I’m not using AI content generation for some of my art and figures. I’m also quite certain that LLMs will enable a new generation of content-aware layout tools that can make intelligent font, layout, heading, and other styling choices for me in an instantaneous and automated fashion. So much for the entire “Production” category.
Under “Revisions,” content edits have remained untouched by software, but article spinners can already handle this, at least in theory. Some of the tooling needs to be built out, and on the model side, the input token windows will need to be enlarged. But a really solid set of content edits — i.e., high-level reorganization of an article draft for clarity, virality, conversion, or whatever other goal — is easily within view in the very near term.
Language models are already good enough to automate the process of turning a crudely recorded set of facts and statements into a polished essay, so the step of organizing your thoughts into a draft will get eaten pretty shortly. If you’re a content person who is not in marketing and/or SEO, you’re probably not using these tools yet. And indeed, they’re probably not good enough right now — I certainly haven’t started using any such tools for this Substack, yet. But I can say with a high degree of confidence that any quality problems have already been fixed in models that haven’t been exposed to the public, much less productized. All of that will happen in the next year or two.
This leaves the research and creative synthesis steps as the last bastion of human value-add… except not really. If you’re reading this and you think an ML model will never produce a natural-language document — research paper, book, essay, etc. — that experts agree has made a genuine contribution to the sum total of human knowledge, I’d like to suggest that you will be disabused of this notion no later than the end of 2024. Seriously. ML models will produce novel insights that specialists agree are interesting and useful, and they will do this very soon.
This phenomenon of ML models introducing novel, innovative concepts and techniques that humans are learning from has already happened years ago in the game of Go via AlphaGo.
Humans will still do some things that machines will do at scale
I want to emphasize that in the above discussion, I am not claiming that we humans have totally quit doing all the writing steps above, or even are no longer being paid to do them.
You can still get a typing job as a court stenographer.
Typesetting is still a profession, and at some specialty presses, old-school typesetting with physical type is still being done.
In general, for whatever it is that robots or computers are now doing at industrial scales, you can still find some boutique niche where humans are still getting paid to do that same thing.
Similarly to the above, there will be places that continue to hire and train humans to do any or all of the higher-value tasks that machines will largely take over. But this will be a niche thing, usually limited to cases where the finished product is some boutique cultural object that’s made the way it is for status effects.
In industrial settings where the bottom line governs and the work of the models is good enough to pass some quality threshold, a rapid, catastrophic collapse in the market value of all the kinds labor that ML models can do — don’t kid yourself, because I do mean all of it — will take place.
To return to covid analogies, if you work in a creative field or in any job where most of your labor involves complex symbol manipulation, the production of cultural objects, and reasoning about abstractions, then you should be looking at what’s happening in art, SEO, and copyrighting the way that I was looking at OSINT videos of people passing out in Wuhan in early January 2020 and thinking, “whatever this is, it’s gonna change all our lives, and we’re probably all gonna catch it.”
Thanks for posting this, it's a nice inside view, based on a model of how technology may change, of what to expect.
But I don't think the financial markets agree with you. If there'll be a very near-term step change in the economy's productive capacity, to a higher growth rate regime, and it's foreseeable, we should see signs of it now. Expecting we'll all be much richer very soon should reduce savings rates (why save if we'll all be rich soon?), which should push up interest rates.
The T-bond market shows no signs of that. So, y'know, are you short Treasurys? :) There's money on the table.
I already see "this must be machine generated" used by normies to dismiss someone who writes redundant opinions.
It will become a lot easier to dismiss the long tail of human creation, which is most of it, as worthless.
My trained GPT-2 generates Hungarian poems; when it does so brilliantly, it's bad for Hungarian poets. But poetry hasn't been a meritocratic field for a long time. It had state funded gatekeepers, fashions, favours, snobbery. Since the mid-2000s, Web 2.0, the internet allowed everyone to publish poems, and those who did so, were and are dismissed by the gatekeepers as common trash. Now there's a chance that the masses will do the same to the privileged few by assuming ML behind poetry.
ML is a force of corrective dismissal that should make arts more honest.