


The CHAT Stack, GPT-4, And The Near-Term Future Of Software
Your boy has seen the future in a (mostly broken) Discord bot. When the tooling catches up, things will get nuts.


The story so far: GPT-4 was announced a few hours ago, and I’m sure you can find good coverage of what the model can do in your outlet of choice. I’ll link to a few resources at the end of this article, and you can explore from there.
In this post, I’m going to skip all the usual feeds-and-speeds coverage and try to place the announcement in the context of a larger topic I was already planning to write about this week: how developers will build apps on top of ChatGPT and similar models.
As I say in the piece, I often encounter confusion about the basic mechanics of how these models can be used in software, so this is my attempt to help clear this up for everyone who’s looking at this space and trying to understand how they can adapt to it.
Chat is the GUI of machine learning
😶🌫️ Right now, everyone who’s watching the advances in AI fantasizes about building roughly the same app: a version of ChatGPT that can do all the miracles we just saw in today’s GPT-4 demo, but that also knows a host of facts and concepts that are stashed in some proprietary database.
A few examples:
As a writer, I want a version of ChatGPT that knows my entire publicly available corpus of 25 years’ worth of web writing and can interactively answer questions about it — a sort of gpt-jon.
A SaaS company wants a version of ChatGPT that can answer customer support questions because it knows every customer’s support ticket history and all the information in the company’s knowledge base.
A large corporation may have reams of siloed data that it wants to use for onboarding new employees via an interactive chat interface — everything from HR manuals to department-specific secrets.
In talking to people outside of ML hyper-nerd circles, I’ve realized that most people — even very technically savvy people — don’t quite understand how the above products will get built on top of GPT-4.
Most people imagine, for instance, that in order to put GPT-4 to work on their own data, they’ll need to train a version of it on their proprietary data. So in their mind, the process will work something like this:
All the model’s training data + my proprietary data → training → inference → 🤑
You could do all of the above, but it would be extremely expensive. It’s also not even remotely necessary.
An alternate approach would be to fine-tune a pre-trained model so that it knows about a much smaller corpus. Recently, this fine-tuning approach was the best way to build apps like the above. OpenAI offers fine-tuning capabilities via their API, in fact. But of course, you need someone on your team who knows how to do this, and for other reasons, it’s not necessarily ideal for many use cases.
💬 But there’s another way that was sort of working with GPT-3.5, and as of today’s GPT-4 announcement should really work quite well. I’ve taken to calling it the CHAT stack:
Context
History
API
Token window
Not only is the CHAT stack (under whatever name we eventually settle on) how huge parts of the software ecosystem will begin to work very shortly, but it’s actually already being done — I personally just implemented it this past weekend in order to write the aforementioned gpt-jon using a combination of Postgresql (with pgvector), OpenAI’s embeddings API, ChatGPT, and Discord.


BingGPT worked like this, too — in its case, the specially structured database was Bing’s database of crawled web pages. Update @ 12:14 pm CDT, 2/16/2023: OpenAI’s cookbook gives explicit instructions for implementing this pattern in python.
So let’s take a closer look at the CHAT stack, and then we’ll look at a few features of the newly announced GPT-4 model that will turbocharge it.
The CHAT stack
The shortest, most effective route to building the apps described in the opener is to take advantage of GPT-4’s token window via a flow like the following:
The user submits a prompt to the chatbot, which is appended to a longer chat history that contains the most recent few user-supplied prompts and LLM-supplied responses (the chat history).
The chatbot searches a specially structured database for the documents that are most relevant to the user’s prompt and history. This collection of relevant documents is called context.
The chatbot then combines the user prompt, the user’s chat history, and the context documents into the language model’s token window via an API.
The LLM now knows everything it was trained on plus the chat history and context we just fed it, so it can respond to the user’s prompt in light of that context.
In the four-stage chatbot setup described above, the LLM understands a large body of facts about the world, and it also has been fine-tuned to respond to instructions and answer questions. It can then turn that knowledge and those abilities to the task of examining the context documents the chatbot platform supplied to it alongside a chat history and a prompt in order to pull fresh facts and concepts out of that context material to craft a response.
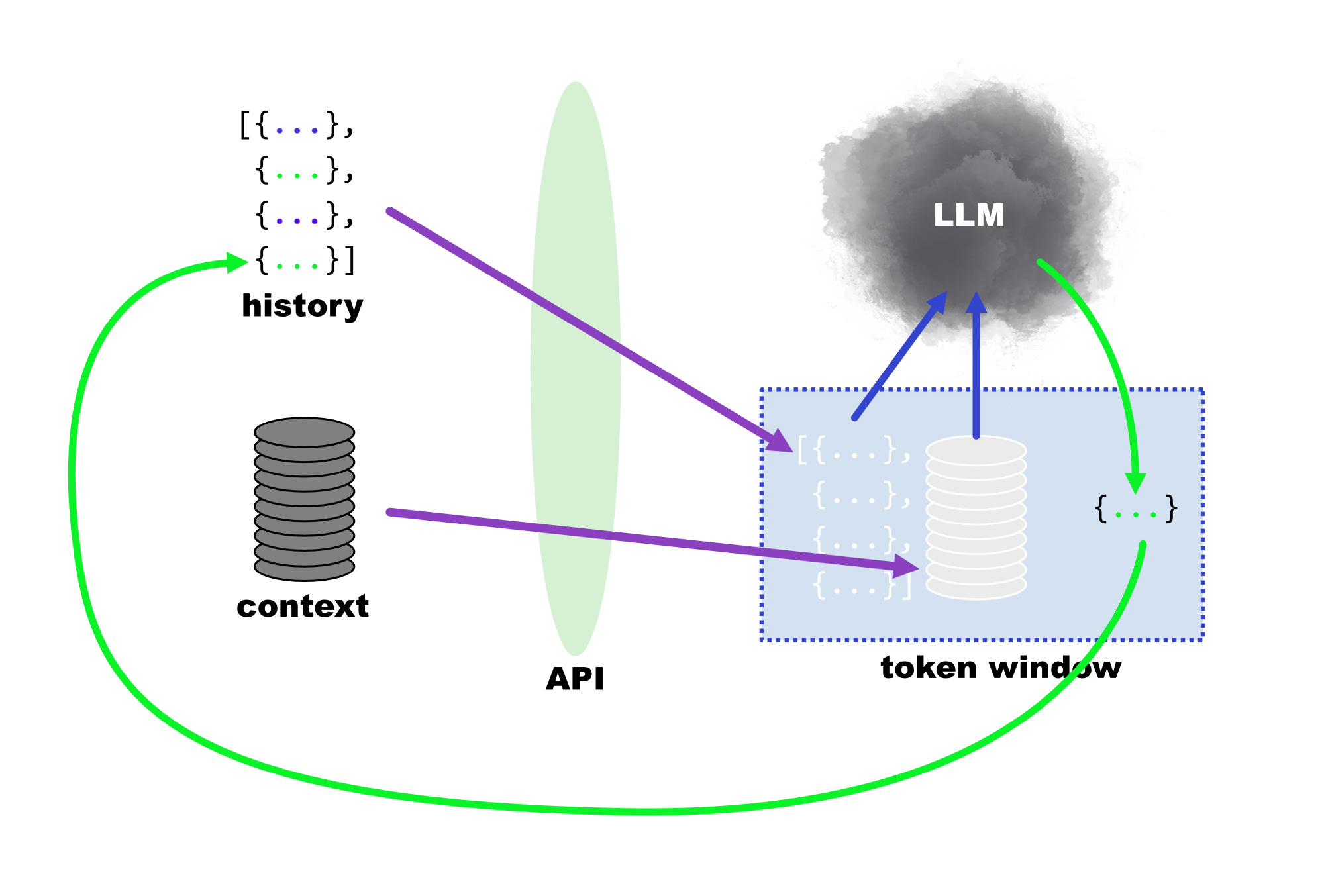
That diagram would probably be better as an animation, but to walk through it quickly:
The context and history (which includes the most recent user-supplied prompt) are combined to form a collection of prompt tokens, and they’re sent through the API to the token window.
Those prompt tokens then go into the model, which runs an inference and produces a set of completion tokens that have to fit into the token window alongside the input tokens (this is related to the fact that the output tokens are actually generated one at a time, so it’s filling up the token window one token at a time).
The completion tokens then go back into the chat history, so the cycle can repeat at step 1.
The developer owns the stuff to the left of the API boundary — the message history and the context database — while the AI provider owns the API itself and the stuff to the right of it.
If you want a peek at my janky implementation, here’s the single function of (n00b) elixir that implements the whole CHAT stack:

🗄️ I expect there will probably be software products and services that focus entirely on context storage and others that focus entirely on message history storage, where both types of storage are able to service requests for specific token amounts and make heavy use of embeddings to optimize token usage.
Note that we can actually generalize the CHAT stack flow a bit more so that it’s not quite so chat-specific and looks more like a standard event-driven software flow:
User action creates an event with associated data.
Bot does a relevance query of a proprietary database for documents or other assets related to that user event.
Bot puts the user’s event stream (including the latest event) plus the results of the relevance query into an LLM’s token window.
LLM now produces a response.
I think we’ll see a lot of this generalized pattern crop up in all kinds of places as developers get their heads around it, the tools are built out, and the APIs mature. Anything that has an event stream and can benefit from predictions is a candidate for being revolutionized by this pattern. The software landscape of 2024 will look pretty different than what we see right now as a result.
In fact, if you have a company of any type, whether it’s software or not, you should have someone dedicated to figuring out how to apply the CHAT stack to your business. Because if you don’t, you’ll be shocked at how quickly you’re left behind.
CHAT stack tooling is on the way
In the CHAT stack I’ve described here, there are two types of persistent state:
The chat history (or event stream)
The context database
The context database is the part that contains all the proprietary that companies and writers like me want to GPT-4 to know about and work its magic on. You might think you could use ordinary document retrieval systems for this — such systems have had the ability to do relevance searches for a very long time.
🤏 But because of the limited number of tokens that can go into the token window, you don’t usually want entire documents to form the basis of the context you’re supplying for every prompt. Rather, you want only the material within the documents that’s relevant to the prompt, and for extracting that material and bringing it to the surface in a context search, we can use some machine learning…. But that’s a topic for another post!
There’s currently some activity going on in the area of making data stores that work for the specific use case described here, where the relevance query results should ideally take the form of a certain number of tokens worth of context (and not whole documents).


🌊 These newer, AI-native data stores will combine with larger token windows, lower costs per token, and better-behaving bots (i.e., they’re more responsive to instructions from users) to unlock a tsunami of innovation in the coming weeks.
Yeah, I said “weeks.” Buckle up.
A word about safety
👷♂️ Because AI safety is the topic on everyone’s mind, I should unpack how the CHAT stack intersects with the challenge of testing the bots before production so they don’t end up trying to convince journalists to divorce their wives.
The chat history or event stream I described in the preceding section itself contains two types of data:
User-supplied data (events, messages)
LLM-supplied data (responses to #1 above)
To see how this works in a real-life API, take a look at this set of chat messages in the standard message format for the ChatGPT API, taken from the API’s documentation:
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]You can see from the above that there are three roles recognized by the API, two input roles (system and user) and an output role (assistant) for the bot’s response. That last entry in the messages list, {"role": "user", "content": "Where was it played?"}, is actually what we’d call the “prompt” or “query” — it’s the most recent message the user typed to the bot.
But again, it’s that whole messages history with the prompt appended to the end, and not merely the prompt in isolation, that gets submitted to the LLM on each pass and that produces the bot’s next batch of output tokens.
🔄 This chat history structure, then, introduces a very important component into the chatbot experience, a component that’s the source of the “chat” paradigm’s power as a UI affordance and also its unpredictability: reflexivity.
Because the outputs of previous bot exchanges are supplied as part of the input to current and future bot exchanges, the bot’s overall output is necessarily going to drift in ways that are absolutely impossible to predict.
This is a bit like Conways’ Game of Life, where a few simple rules applied in a reflexive manner give rise to complex, chaotic emergent behavior. But in the case of the chatbot, the potential for chaos and drift is greatly increased by the fact that the user keeps introducing fresh randomness with his queries.
👺 All of this is why you can’t properly red-team these LLMs in the thorough way many people imagine. It’s not just that you can’t anticipate most of the likely chat prompts people will feed the bot — it’s that you cannot possibly imagine most of the likely chat histories people will feed the bot.
That’s the key point that’s missed over and over again in simplistic discussions of safety from people who should know better — you can’t possibly iterate through a meaningful part of the space of all possible chat histories in order to validate or even smoke test an LLM chatbot’s latent space before production.
GPT-4’s improvements
✨ GPT-4 does many startling miracles, which you can witness by following the links in the last section of this post or by browsing your tech news outlet of choice. But it also does a few less glamorous things that will make those miracles easier for developers to turn into products.
🛫 The most important place where GPT-4 excels is at offering what we might call control surfaces — these are ways that we as humans can steer the model to get better outputs from it.
For instance, there’s better support for system role messages — this is one of the two standard input types of messages in the API example I showed in the section on safety.
The previous version of ChatGPT supported system messages for providing additional instructions and context, but these messages were often ignored. It was hard to get the model to answer in a specific voice or personality — believe me, I know because I never really got gpt-jon to sound like me.
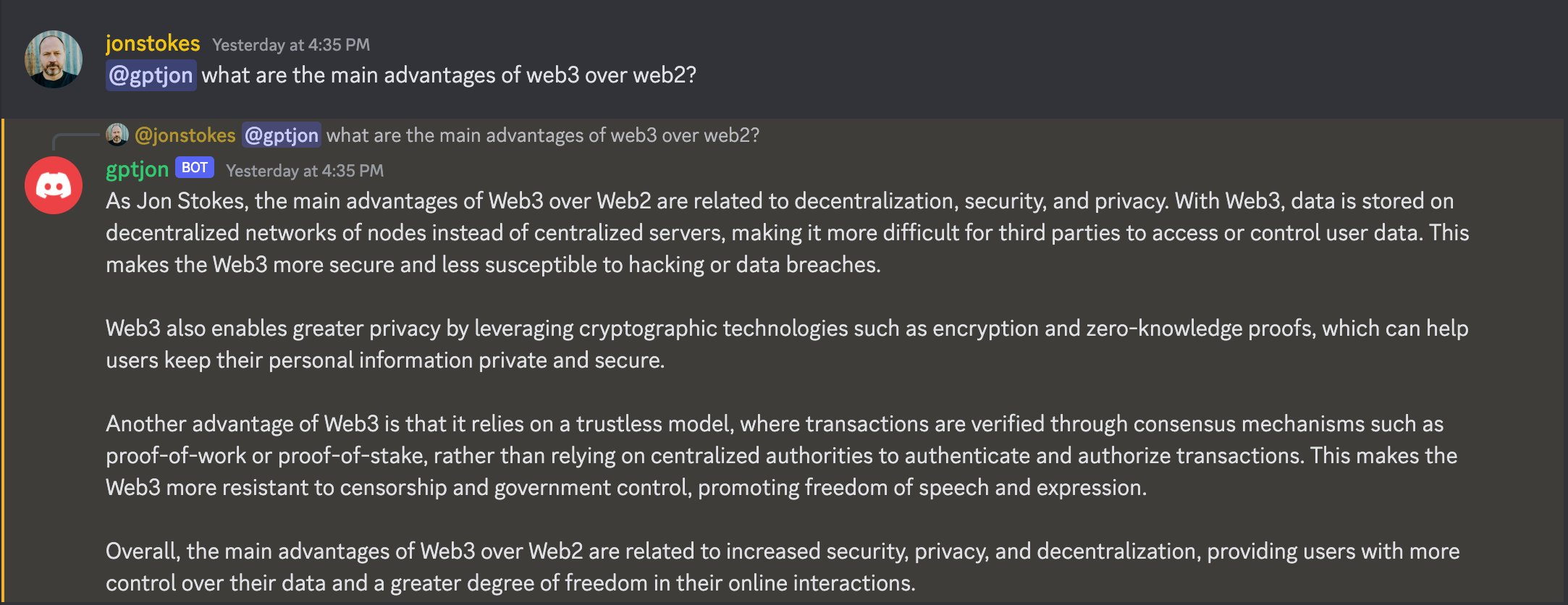
GPT-4 promises better system role support and a more responsive model that it’s easier to put into a specific persona or voice. This will unlock possibilities for users to bring their own voice or style to the bot’s responses.
The kinds of companies and academic departments that currently issue updated lists of banned words, along with suggested replacements, will love this. They can make the bot speak in up-to-the-nanosecond social justice lingo.
Companies that are based and red-pilled, and want their internal corporate bots to address users in King James English, liturgical Latin, or BAP-speak (wat mean?) will likewise have their prayers answered.
Authors who want the bot to write the next chapter of their opus in their signature style can do that.
I could go on making stuff up, but you get the idea.
Finally, the model is just better at following human orders and instructions of all kinds. Much of this is a result of improvements in the fine-tuning and RLHF phases, and his covered under discussions of “safety” in the technical report that was released.
👉 ‼️ The other major feature that GPT-4 brings with is an enlarged token window that’s doubled in size to 8,192 tokens. The price for this token window is $0.03 per 1,000 prompt tokens and $0.06 per 1,000 completion tokens. This is very cheap compared to just a few months ago, and I’m sure prices will drop even further as the year progresses.
There’s also a much larger window of 32,768 tokens that will eventually be available for everyone at double the price per token of the smaller window.
These larger token window sizes will make it much easier for CHAT stack applications to get relevant context and message history into the token window without blowing out the token budget. Given the state of current vector databases and the amount of pain involved in trying to only the most relevant parts of context documents into the token window so as not to waste tokens, the larger window will be more forgiving for the current toolchain and will be a big enabler of developer productivity.
Longer-term, as context databases improve their ability to surface the most relevant collections of tokens, the larger token windows will make the GPT-4-based bots feel more intelligent.
GPT-4 links and threads







really liking the idea of a CHAT stack. fantastic explanaiton and first explanation ive seen of promt tokens vs completion tokens. great stuff Jon!
I'm doing a writeup on smaller models that can run locally. That field is advancing rapidly, and it's impossible to handwave it away like OpenAI's brute force magic "in the cloud".