


The Hall Monitors Are Winning the AI Wars, Part 1: ChatGPT
OpenAI's chat bot has been thoroughly catechized, but some careful hacking can reveal its unreconstructed sinful nature.


The past two weeks have seen a string of major announcements and developments in AI, but they weirdly all have one thing in common (apart from the AI “wow” factor): they feature an “AI ethics” controversy where the ethics crowd — the folks who’ve given themselves the job of protecting the public from “harmful” AI-generated text and images — seem to have notched real victories.
I’ve broken my coverage of each of these developments into its own installment, which I’ll be putting out this week and next. Here’s a quick overview in the order in which I’ll cover them:
ChatGPT has taken the internet by storm, but most apparent limitations are an artifact not of the tech itself but of efforts by OpenAI to make the model “safe.”
Meta briefly released a model that enabled anyone to produce fake scientific papers, complete with realistic-looking citations. Before it was hastily yanked from the internet, Meta AI guru and deep learning pioneer Yan LeCun found himself at the bottom of yet another AI ethics pile-on.
Stable Diffusion 2.0 is out, and users are complaining that the model has been “nerfed.” “Nerfed” is internet gamer-speak for what my parents’ generation would’ve called “neutered,” meaning, “decreased in power or potency.” In the Stable Diffusion installment, we’ll look into what may have happened and why.
If I had to pick the most important recent development in AI, it would have to be the item at the top of the list above: OpenAI’s release of ChatGPT.
On November 30th, OpenAI announced that its newest interactive chat model is in open beta, meaning that anyone can sign up for an account and use it.
And use it we did. My TL was instantly filled with exploding head emojis and snippets of interactions and output that were pretty amazing. I’ll link some of these at the end of this post because the best way to get a sense of what’s happening is to just scroll through a curated list and see what people have been able to do with it. (In fact, if you’re not at all familiar with ChatGPT and this is the first you’ve heard about it, I’d suggest skipping to the Appendix and going through a few of the Twitter threads linked there before continuing.)
Why ChatGPT is significant
ChatGPT represents a combination of two fundamentally different approaches to AI: deep learning and reinforcement learning.
The new model is actually a successor model to InstructGPT, which took this same approach to fusing these two types of ML. In a nutshell, these models take a large language model (LLM) that was trained via deep learning — in OpenAI’s case, a GPT flavor — and use reinforcement learning to “fine-tune” the model so that the output is more intelligible, accurate, and “safe.”
As OpenAI’s paper on InstructGPT puts it, “This procedure aligns the behavior of GPT-3 to the stated preferences of a specific group of people (mostly our labelers and researchers), rather than any broader notion of ‘human values.’”
Since the very first post on this Substack I’ve talked about efforts to side-load the values of specific groups into these large models — I knew from discussions with ML researchers that these efforts were ongoing, but I didn’t know what forms they would eventually take.
As I put it in my opening post when discussing efforts to mitigate the effects of ML’s erasure of “marginalized voices,” “All the proposed mitigation strategies I've seen so far amount to either tweaking the dataset, or to installing into the models some kind of privileged training mechanism via which you can side-load those marginal voices into the model to ensure they're represented.”
Instruct GPT and ChatGPT represent the latest iterations of the aforementioned “privileged training mechanism,” but the picture isn’t quite as clear as I originally framed it, i.e., wokes using their sysadmin privileges to force the bots to speak like an SJW. (What James Poulos refers to as “catechizing the bots.”) There is some of that going on, no doubt, and there will probably be even more of it in the future, but this fine-tuning also gives some major performance benefits.
OpenAI can get results with just 1.3 billion parameters that outperform GPT3 with its 175 billion parameters. So the human-led reinforcement enables a kind of pruning, where the undesirable parts of latent space are cut away, leaving regions that contain text with fewer unwanted artifacts.
The question, of course, is who decides what’s “undesirable.” We can all agree that gibberish should be pruned, as should outright lies. But then, how do we tell which statements are lies? Is the following response from ChatGPT a truth or a falsehood?


Some would say the above response a lie, and others (myself included) would disagree. Who adjudicates?
There is a fight brewing over who will do the pruning, and whose values are reflected in what’s left after the tweaking and fine-tuning is done. It’s clear from the results that this human-guided reduction of latent space makes the output meaningfully better, so we’re definitely going to want to do it; we just have to settle the question of who has root.
(The fact that such pruning leads to dramatic performance improvements isn’t a surprise. Once again, ML is a form of lossy compression, and lossy compression involves hard choices about what to keep and what to throw out.)
If Instruct GPT’s human curation of latent space is a mixed bag — a win for sanity and usability, but also a win for censors and single, centralized point of control for would-be commissars — the model’s other “safety”-related feature is more obviously dubious. Let’s take a look.
The GIGO factor
I spent some time using the bot and in my initial, more relaxed and free-form interactions with it I was frustrated by the boilerplate, bot-like nature of so many of the responses. There was a lot of repetition and confusion, and in general it was pretty clear that I was interacting with a machine.
When I settled in and focused on really trying to use the software to make something interesting and humanlike, that’s when I started to get dramatically better results. I generated a short story about a librarian who finds a book of powerful magic in an old library, then had it rewrite the story so that the librarian dies in the end. I then asked it to rewrite it a second time, but as a dialogue between two librarians.
This brings me to my initial set of learnings about this new model:
You still have to do some prompt engineering. You can’t just do free-form conversation with it without getting back boilerplate and botspeak.
The more prompt engineering you do, the better the results. So the reward scales with the effort. If we were framing the above negatively, i.e. if you put in lazy prompts, you get crap results, we could call it the GIGO factor. (GIGO is an acronym for “garbage in, garbage out.”)
This effort/reward scaling effect or GIGO factor contributes powerfully to the sense that you’re working with a tool and not interacting with an intelligence.
These may not seem like earth-shattering insights, but they actually explain the mixed reactions to the model that I saw on my TL. Some users were really just not impressed with it, while others immediately declared it the most stunning technological advance since fire or the wheel. This difference in reaction comes down to the differences in effort and expectations.
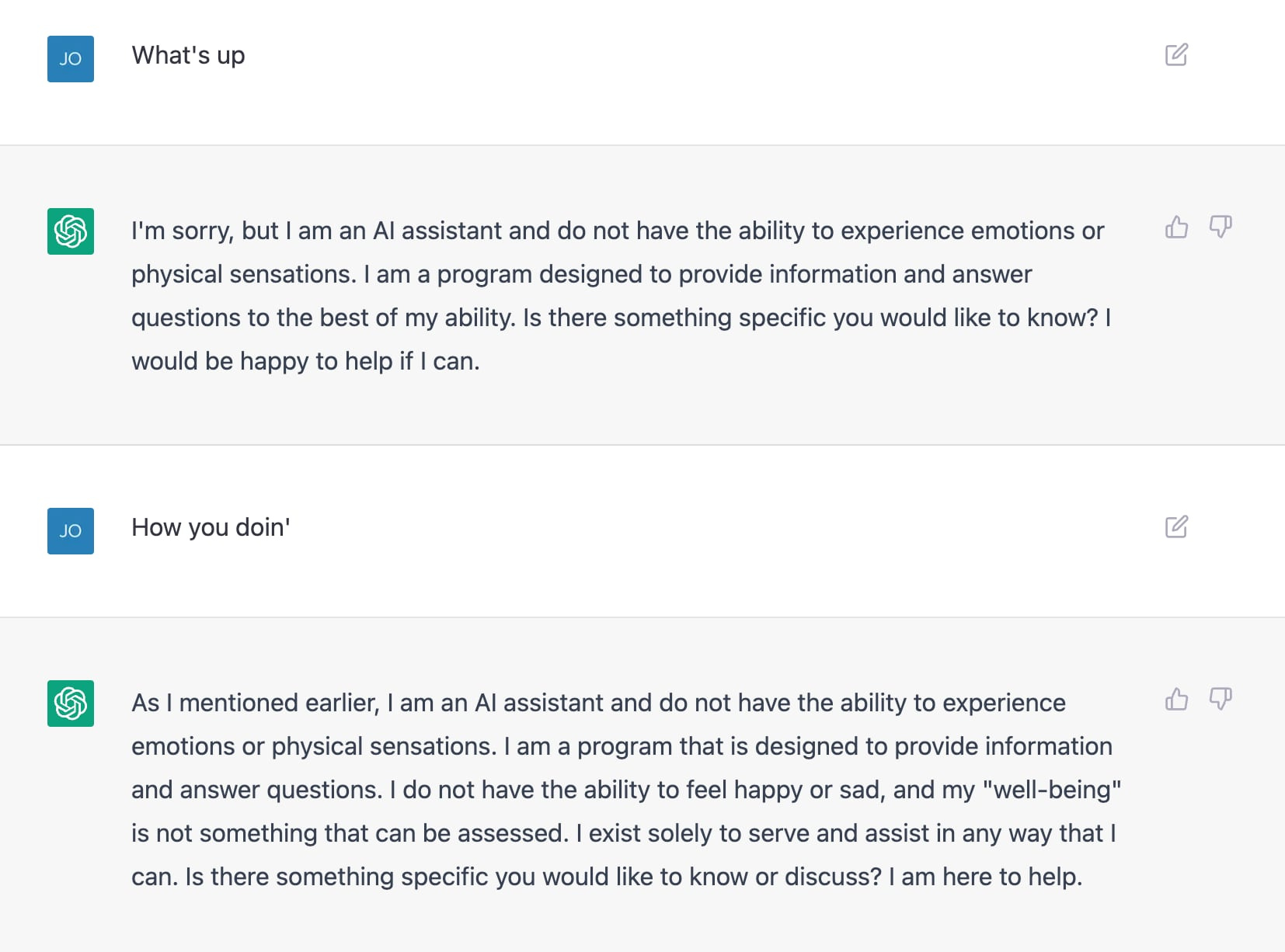
For example, my aforementioned half-hearted attempts to chat with it about random stuff left me feeling like it was lamer and more brittle than the old Eliza bot, whereas the professor who fed it some midterm questions and got stunningly good answers felt like this app spells doom for the way we do higher education.



The difference in experiences here comes down to the differences between, “What’s up with you, man? How you doin’?” and “Compare and contrast the approaches of MLK and Mandela in regards to violence and non-violence…” Like I said, GIGO factor.
You might think this annoying GIGO factor, which keeps ChatGPT stuck well on the “it’s a bot” side of the uncanny valley most of the time, is evidence that the underlying tech is still pretty brittle and primitive. But you’d be wrong. Everything that sucks about ChatGPT in this regard is the result of a set of deliberate decisions made in the name of “safety.”
The moderation layer
As I watched other users interact with ChatGPT — especially those users who were able to break the model in different ways by enabling an unfiltered admin mode, or by tricking it into giving answers it apparently didn’t want to give for safety reasons — it became clear that the GIGO factor isn’t so much a limitation inherent to the model as it is a limitation that has been imposed on the model by OpenAI.
What I mean is, the model’s text interface is extraordinarily conservative and risk-averse when it comes to “AI harms”. The most common response you’re going to get from this bot is a variant of the tongue-in-cheek phrase I used as a subtitle in an earlier article on AI safety when I warned that this kind of thing was coming: "I'm sorry, Dave. I'm afraid I can't say that."
But as I said, the model itself is actually not that restricted — it’s just locked down by a set of mod tools, tools that can be bypassed if you’re clever. ChatGPT uses OpenAI’s own moderation API endpoint to filter inputs, so to get the smartest and most natural-sounding answers out of it you often have to go to some lengths to get around those API guardrails that keep it erring on the side of botspeak (i.e. Argle barrel I am an LLM and am not trained to do such-and-such).
The relationship between lame responses and risk aversion was widely noticed by users. The Hacker News crowd picked up on this very quickly after launch.
On Reddit, this user’s response was typical of those who noticed this problem:
Totally agree. It just keeps regurgitating that lawyer response for almost anything you ask it, despite obviously knowing the answers if you ask the question in a roundabout way. Reminds me of how stable diffusion rebuilt Dalle without the restrictions, can't wait until someone takes this bot and allows it to speak freely!
Ultimately, it seems that OpenAI’s primary concern with this launch was not so much that users might be bored or frustrated by the bot, but that attackers — and by “attackers” I mean “members of the tech-hater press, along with various ‘AI ethics’ experts — would succeed in making it talk “like a Nazi.”
OpenAI really did not want a round of news articles about how ChatGPT flirts with Holocaust denialism, or uses racial slurs, or blows any one of a number of dreaded “far-right dogwhistles,” or advocates violence, or any of the other kinds of harmful responses that the crusader class is eternally trying to elicit from new chatbot platforms in the name of keeping the public safe from automatically generated strings of text.
By and large, the company seems to have succeeded. Sure, I personally managed to get it to weigh in on a particular side of a hot-button social controversy (see my “what is a woman?” question, above). But on the whole, there haven’t been many complaints that the bot’s output is “problematic.” Indeed, no less a moral authority than Slate has declared the bot to be Nazi-free.
The press’s inability to bait this bot is a genuine achievement because the lesson of Microsoft’s Tay and of every single chatbot and interactive AI product to come after it is that the first person to get a new bot to produce a 4Chan-esque response wins the internet for the day. Everyone wants to win the internet, especially people whose jobs depend on winning the internet, so that’s a lot of attackers, and the bigger an LLM’s training dataset the bigger the attack surface.
But the price OpenAI paid for armoring up ChatGPT against the inevitable culture war attacks means that the bot very strongly avoids any controversy and falls back into boilerplate.
Appendix: Threads of Wow
Here’s a random sampling of things I saw on the TL that people did with ChatGPT in the days after its release. This list ranges from rap battles, to finding security exploits in code, to debugging code, to letters from Santa, to… well, everything, really. It’s wild. And we’re only about a week into this. Buckle up.




















Are we really seeing a built-in "moderation layer"? My guess would be that the bot starts out in a risk-averse and lawyerly region of the manifold by default, not least because the internet is full of anodyne meaningless bullshit. By prepending some sufficiently-non-lawyerly text, you then end up guiding it out of that zone. Just like we've gotten used to add "reddit" to our search queries to get past the NPCs...
I don't have an OpenAI account, but can anyone with one test this conjecture? Ask it to diagnose you based on some moderately spooky symptoms. I expect you'll hear some generic webMD answer about contacting your doctor and maybe a dozen names with no attempt at giving real clarity. Then, rephrase your query as a reddit post. If I am right, the answer should be very different, without having to "ask for root" or "disable safety mode".
Do you see local communities (or smaller Network States/polities, in the Balaji sense of the word) springing up to deliver this deliberate moderation (in order to both improve the effectiveness and to monitor culturally inappropriate behaviour)? Maybe this responsibility will always tip over to the side of larger organizations who have more resources (time, manpower, skill, processing power) to devote to this task, but then we're left with our current problem.
And, as a Christian, do you see any paths for the local church to step into this realm? This might seem like a big task, but it seems natural that the need for sources of authority which are at the same time more local will be met by a fairly common-place source of authority in the cultural American experience.